Занятная статья по всем параметрам, а вышла еще в 21 году😯 . Во-первых, поднимается вопрос исследования встраивания эмбедингов, во-вторых, перенос с одного языка на другой, в-третьих, уменьшение количества параметров при тренировке, так еще и вдовесок "как эффективно уменьшить количество параметров, не потеряв качество"
Прогрев закончен, я начну. Во-первых авторы для исследования берут encoder-decoder для решения проблем задач перевода, но мы мыслим глубже😵 и проецируем на архитектуры, которые тоже содержат кроссэтеншен (вся соль статьи вокруг него). Например, можно вспомнить о том, что мультимодалка завязана на этом механизме 😳
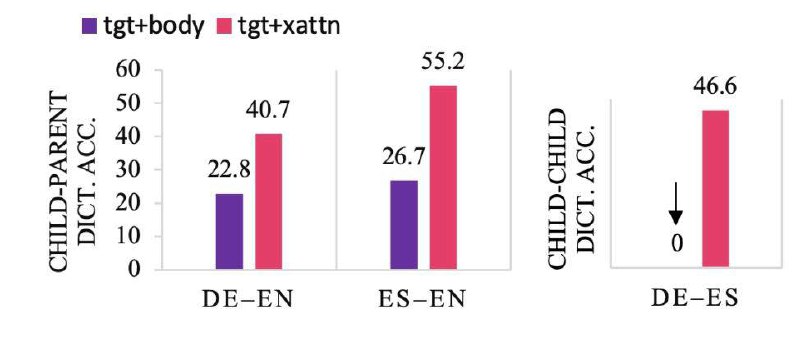
Так вот, авторы эксперементально доказывают, что метрика остается почти на одном уровне при обучении связки эмбединги + кросэттенш и всей модели целиком (см скрин 1). Но это еще далеко не все🤪 , далее начинается, пожалуй, самая интересная часть эксперимента. Они берут слова на одном языке (например немецком), переводят их в эмбединги, а потом смотрят, какой французский эмбединг больше всего похож на немецкий. Если такая пара слов (немецкое и французское) есть в уже готовом словаре MUSE (назовем золотым стандартом) , они считают, что все сработало верно.
См скрин 2, где accuracy - это просто доля правильных пар слов. Например, если из 100 проверенных пар слов 55 есть в словаре MUSE, то метрика - 55%
Из всей статьи напрашиваются просто замечательные выводы:
При тюне кросэтеншена и слоя эмбедингов можно уменьшить количество параметров модели; Вторая часть эксперемента плавно подводит к устранению забывчивости модели при таком тюне
🖥 ну а в коде можно найти пару лайфхаков для инициализации нового языка в модели
P.S. Активно слежу за событиями последних дней, надеюсь на мир во всем мире и что у вас все хорошо💛 💛 💛 🇮🇱
#PEFT
Прогрев закончен, я начну. Во-первых авторы для исследования берут encoder-decoder для решения проблем задач перевода, но мы мыслим глубже
Так вот, авторы эксперементально доказывают, что метрика остается почти на одном уровне при обучении связки эмбединги + кросэттенш и всей модели целиком (см скрин 1). Но это еще далеко не все
См скрин 2, где accuracy - это просто доля правильных пар слов. Например, если из 100 проверенных пар слов 55 есть в словаре MUSE, то метрика - 55%
Из всей статьи напрашиваются просто замечательные выводы:
При тюне кросэтеншена и слоя эмбедингов можно уменьшить количество параметров модели; Вторая часть эксперемента плавно подводит к устранению забывчивости модели при таком тюне
P.S. Активно слежу за событиями последних дней, надеюсь на мир во всем мире и что у вас все хорошо
#PEFT