МОЕ ЛЮБИМОЕ, выяснение где же кроются фактологические зависимости у моделей.
Многие подобные статьи не то, чтобы решают проблему галлюцинаций, так как в принципе неизвестна причина такого поведения декодеров. Но в последнее время исследователи приходят к выводу, что возможно причина кроется в функции правдоподобия между распределением данных и моделью. Поэтому не зная факт, модель начинает присваивать ошибочно большую вероятность неизведанному, просто потому, что она должна найти вероятностный токен🐧
Авторы ссылаются на статьи поиска фактологических зависимостей в трансформерах, которые в основном приходят к выводу о проявлении низкоуровневой информации на более ранних слоях, и более важной для семантики языка на поздних слоях, подобно алгоритму решающих деревьев. Так вот, как же убрать false позитивы предсказаний, если у нас есть на ранних этапах более низкоуровневая информация, которая может перекрыть нестабильность вероятностей оценки? Конечно же взять argmax между этими слоями, aka DoLa)) (тык, тут статья)честное слово, я с такими оригинальными решениями, свой диплом бакалавриата писала .
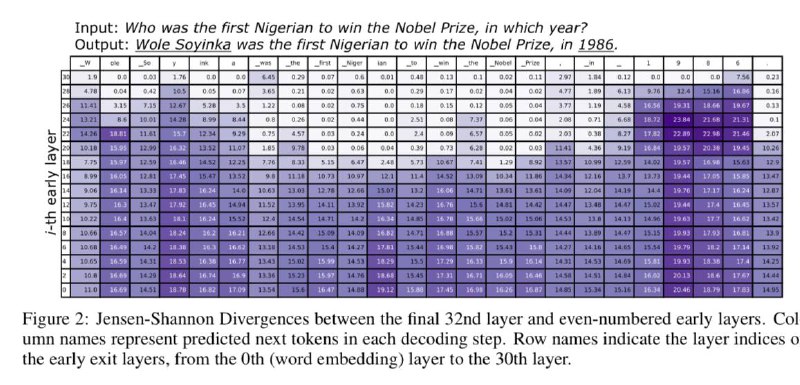
Ну вот, чтобы доказать отличие распределений вероятностей, авторы даже построили матрицу измерения дивергенции Дженсена-Шеннона (JSD) между первыми и последними слоями. И кончено же обнаружили, что на последних слоях, модель начинает предсказывать факты, которые выучивала. Кроме того, с той же дивергенцией, они еще и выбирают максимально отличающиеся слои, разницу которых в итоге берут для предсказания. Итоговая формулка в третьем вложениикак итог мучительных математических выводов для решения проблемы
🖥 Ну а вообще способ хотя бы можно легко протестить благодаря репозиторию. Так как авторы обещают небольшую задержку, я к своим задачам и проектикам прикручу, посмотрю, что по качеству
Многие подобные статьи не то, чтобы решают проблему галлюцинаций, так как в принципе неизвестна причина такого поведения декодеров. Но в последнее время исследователи приходят к выводу, что возможно причина кроется в функции правдоподобия между распределением данных и моделью. Поэтому не зная факт, модель начинает присваивать ошибочно большую вероятность неизведанному, просто потому, что она должна найти вероятностный токен
Авторы ссылаются на статьи поиска фактологических зависимостей в трансформерах, которые в основном приходят к выводу о проявлении низкоуровневой информации на более ранних слоях, и более важной для семантики языка на поздних слоях, подобно алгоритму решающих деревьев. Так вот, как же убрать false позитивы предсказаний, если у нас есть на ранних этапах более низкоуровневая информация, которая может перекрыть нестабильность вероятностей оценки? Конечно же взять argmax между этими слоями, aka DoLa)) (тык, тут статья)
Ну вот, чтобы доказать отличие распределений вероятностей, авторы даже построили матрицу измерения дивергенции Дженсена-Шеннона (JSD) между первыми и последними слоями. И кончено же обнаружили, что на последних слоях, модель начинает предсказывать факты, которые выучивала. Кроме того, с той же дивергенцией, они еще и выбирают максимально отличающиеся слои, разницу которых в итоге берут для предсказания. Итоговая формулка в третьем вложении