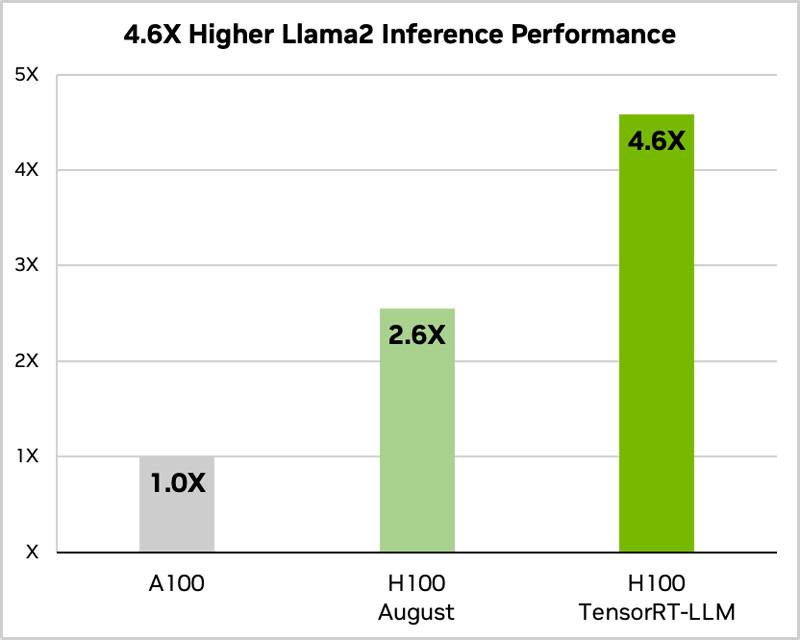
NVIDIA анонсировало по для ускорения LLM для людей без одной почки, но с H100
TensorRT-LLM объединяет компилятор глубокого обучения TensorRT, оптимизированные ядра из FasterTransformer, предварительную и последующую обработку, а также коммуникацию между несколькими GPU/узлами в простом, открытом Python API. Этот API предназначен для определения, оптимизации и выполнения LLMs для вывода в производственной среде
TensorRT-LLM объединяет компилятор глубокого обучения TensorRT, оптимизированные ядра из FasterTransformer, предварительную и последующую обработку, а также коммуникацию между несколькими GPU/узлами в простом, открытом Python API. Этот API предназначен для определения, оптимизации и выполнения LLMs для вывода в производственной среде