Я проснулась после марафона чтения ШАДовской книжки с новыми методами PEFT нет, я еще не помешалась на адаптерах, но до этого не долго 👨🔬
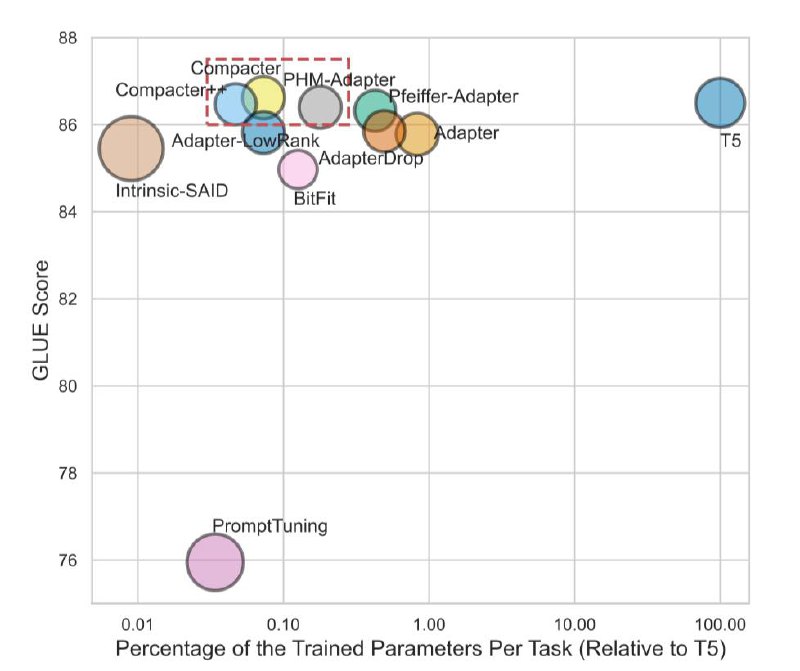
Compacter, 2021 обещает быть лучше по бенчам, чем мой излюбленный AdapterFusion от DeepMind , но в моем понимании в пределах погрешности. Тем не менее график и результаты – 2 первых вложения. При этом в чем еще плюсы: он также как AdapterFusion и soft prompts позволяет в мультитаск, а также решает проблемы reparametrization-based (хранение в памяти проекционных матриц и исходных. При чем мы говорим о времени до LoRA. В связи с этим, да, эта проблема еще не решена ею и существует); нестабильности и чувствительность к инициализации soft prompts; а также увеличению количества параметров на инференсе адаптеров
Небольшое отступление🙃
На первом скрине также видно, что подход сравнивали с методом BitFit (2021), который относится к селективным методам и соответсвенно подобно pruning обучает sparse представление весов сети. Так вот этот метод при оптимизации оставляет не замороженными только bias-terms и последний слой (3,4 скрины вложений)
Итак, за счет чего compacter сильно уменьшает сложность хранения в памяти и решает проблемы раннее существующих методов, описанных выше:
Начитавшись статьи PHM, в которой авторы предлагают эффективную состыковку матриц с применением суммы произведений Кронекера, которая позволяет уменьшить сложность на 1/n, авторы применяют этот подход к специфичным параметрам адаптера и их общим параметрам (а точнее к их проекционным матрицам). Красивую визуализацию этого процесса можно найти на 5-ом вложении. При чем, почему авторы в принципе акцентуируются на использовании общих параметров? так как при «глубокой» цепочке параметров, модель будет способна запоминать только верхнеуровневые статистики обучающих данных.
🖥 Код Comapacter
🖥 Код BitFit
#PEFT
Compacter, 2021 обещает быть лучше по бенчам, чем мой излюбленный AdapterFusion от DeepMind , но в моем понимании в пределах погрешности. Тем не менее график и результаты – 2 первых вложения. При этом в чем еще плюсы: он также как AdapterFusion и soft prompts позволяет в мультитаск, а также решает проблемы reparametrization-based (хранение в памяти проекционных матриц и исходных. При чем мы говорим о времени до LoRA. В связи с этим, да, эта проблема еще не решена ею и существует); нестабильности и чувствительность к инициализации soft prompts; а также увеличению количества параметров на инференсе адаптеров
Небольшое отступление
На первом скрине также видно, что подход сравнивали с методом BitFit (2021), который относится к селективным методам и соответсвенно подобно pruning обучает sparse представление весов сети. Так вот этот метод при оптимизации оставляет не замороженными только bias-terms и последний слой (3,4 скрины вложений)
Итак, за счет чего compacter сильно уменьшает сложность хранения в памяти и решает проблемы раннее существующих методов, описанных выше:
Начитавшись статьи PHM, в которой авторы предлагают эффективную состыковку матриц с применением суммы произведений Кронекера, которая позволяет уменьшить сложность на 1/n, авторы применяют этот подход к специфичным параметрам адаптера и их общим параметрам (а точнее к их проекционным матрицам). Красивую визуализацию этого процесса можно найти на 5-ом вложении. При чем, почему авторы в принципе акцентуируются на использовании общих параметров? так как при «глубокой» цепочке параметров, модель будет способна запоминать только верхнеуровневые статистики обучающих данных.
#PEFT