Вышла модель с адаптивными вычислениями AdaTape от Google
Адаптивность вычислений заботит ресерчеров Google уже долгое время. Тот же MoE, который затрагивался несколько постов выше, яркий пример адаптивности. То есть FLOPs модели зависят от сложности примера, чем меньше сложность задачи, тем меньше модель потратит на вычисления
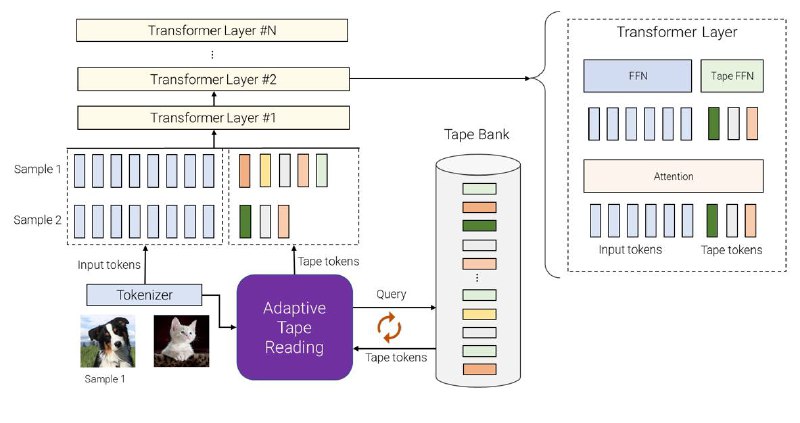
Идея модели в том, что есть Tape Bank, который может управляться входными данными, например путем извлечения некоторой дополнительной информации, которую не содержит исходный набор токенов. Или в Tape Bank может содержаться набор обучаемых векторов. В итоге эти Tape Tokens добавляются к обычным, после чего уже и происходит извлечение информации архитектурой трансформер
🍞 Если совсем просто, можно понять что делает модель следующим образом: представьте, что вы читаете рассказ, но у вас есть не весь текст, а слова маркеры, с помощью которых, вы понимаете смысл книги, но не тратите так много усилий, как было бы при прочтении всего текста сразу
Адаптивность вычислений заботит ресерчеров Google уже долгое время. Тот же MoE, который затрагивался несколько постов выше, яркий пример адаптивности. То есть FLOPs модели зависят от сложности примера, чем меньше сложность задачи, тем меньше модель потратит на вычисления
Идея модели в том, что есть Tape Bank, который может управляться входными данными, например путем извлечения некоторой дополнительной информации, которую не содержит исходный набор токенов. Или в Tape Bank может содержаться набор обучаемых векторов. В итоге эти Tape Tokens добавляются к обычным, после чего уже и происходит извлечение информации архитектурой трансформер