Классический мл больше не будет прежним, или как Яндекс сами запускают вместо градиентного бустинга в каждый дом млщика –трансформер 😮
Наверняка многие экспериментировали при анализе табличных данных с помощью трансформера, а потом ходили в непонятках, почему же все таки CatBoost срабатывает лучше, так вот, теперь это в прошлом. Появился TabR (retrieval для табличных данных), который на бенчмарках бьет град бустинг(логично, иначе статьи бы не было) 🤨
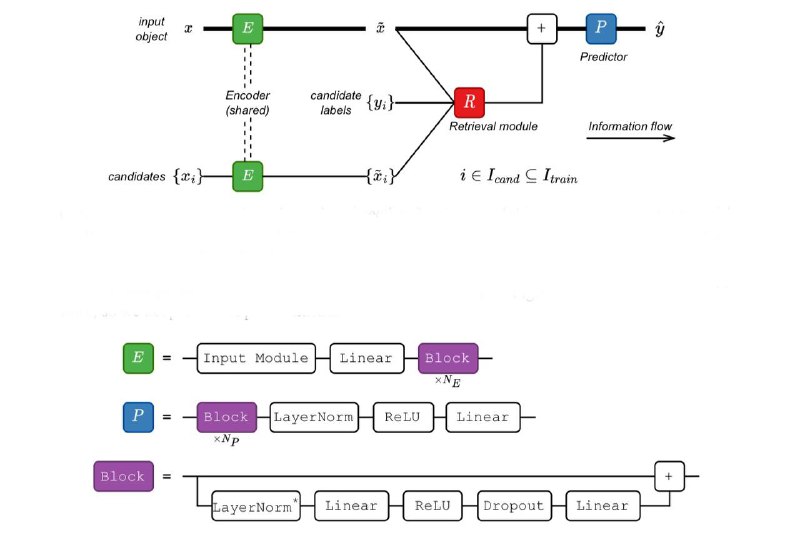
Итак, поверхностно весь секрет в том, что ребята не просто натравливают retrieval, а [энкодят –> на каждую фичу подбирают ближайшего соседа по симилярити –> конкатят с исходным энкодингом –> делают предикт] (см вложения)все, расходимся, чуваки по-умному заюзали идею
Конечно, там очень много деталий в ресерче, про которые хотелось бы упомянуть. (Во вложениях таблица с каждым пунктом, и что он дал на eval)
А) В value модуль аттеншена добавили таргет labels
B) Эмперически доказали, что тут расстояние симилярити надо измерять L2 расстоянием, и отказались от query матрицы соответственно
C) вместо KNN для ближайших соседей взяли DNNR, который содержит поправочный член, которые по сути является производной
D) применили cross attention и убрали скейлинг на размерность матрицы K в формуле внимания
Метрики на бенче GBDT во вложениях
🖥 код
Наверняка многие экспериментировали при анализе табличных данных с помощью трансформера, а потом ходили в непонятках, почему же все таки CatBoost срабатывает лучше, так вот, теперь это в прошлом. Появился TabR (retrieval для табличных данных), который на бенчмарках бьет град бустинг
Итак, поверхностно весь секрет в том, что ребята не просто натравливают retrieval, а [энкодят –> на каждую фичу подбирают ближайшего соседа по симилярити –> конкатят с исходным энкодингом –> делают предикт] (см вложения)
Конечно, там очень много деталий в ресерче, про которые хотелось бы упомянуть. (Во вложениях таблица с каждым пунктом, и что он дал на eval)
А) В value модуль аттеншена добавили таргет labels
B) Эмперически доказали, что тут расстояние симилярити надо измерять L2 расстоянием, и отказались от query матрицы соответственно
C) вместо KNN для ближайших соседей взяли DNNR, который содержит поправочный член, которые по сути является производной
D) применили cross attention и убрали скейлинг на размерность матрицы K в формуле внимания
Метрики на бенче GBDT во вложениях