У меня сегодня появилось немного свободного времени, потому что я больше не смогла смотреть, как моя любимая команда G2 🇪🇺 в киберспортивной дисциплине по CS:GO проигрывает команде из эээ… топ-40, поэтому субботнему разбору статьи быть! 😔
UPD: пока писала вам обзор, они со скрипом, но выиграли.🐶
И не просто так я написала про CS:GO, потому что сегодня я хочу познакомить вас с новой трансформерной моделью от Google DeepMind , и название этой модели созвучно с названием одной когда-то лучшей команды в соревновательном CS:GO — команда NaVI🇺🇦 (Natus Vincere) и новая модель NaViT (Native Resolution ViT). Эх, у NaVI 🇺🇦 тоже сейчас не лучшие времена, болеем за стабильных Heroic 🇩🇰 !
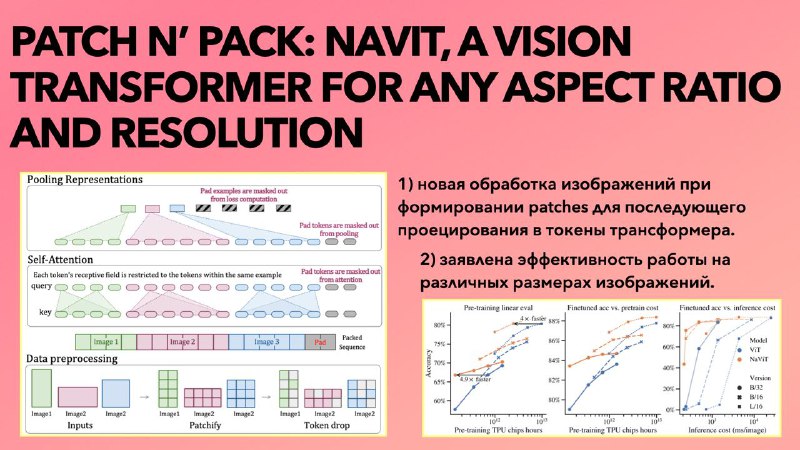
Авторы NaViT подчеркнули следующую проблему, с которой сталкивается каждый инженер/исследователь компьютерного зрения при проведении экспериментов с обучением своих моделей: это выбор подходящего фиксированного размера входных изображений. Конечно, трансформерные модели более гибкие в решении данной проблемы из-за того, что изображение обрабатывается как последовательностей патчей различной длины. Поэтому Google DeepMind решили воспользоваться данным преимуществом, сделав новую модель, которая для обработки входных изображений с произвольным разрешением и соотношением сторон формирует такие последовательности во время обучения. NaViT можно применить не только для классификации изображений и видео, но и для детекции и сегментации, а также для других задач компьютерного зрения. Никаких больше лишних экспериментов (и трат на аренду GPU, и ценного времени разработчика) для определения подходящего размера картинок. 🤩
Cпойлер: опять взяли очередную хорошую идею из NLP.А ДАВАЙТЕ ВЕСЬ NLP ПЕРЕРОЕМ И К СЕБЕ В КОМПЬЮТЕРНОЕ ЗРЕНИЕ ЗАБЕРЁМ 🆗
Из-за ограничения количества символов в сообщение/посте у Телеграма, то читайте остальной разбор здесь. Сторис выкатили, а на развитие функциональности каналов забили!👨🦳
Если нужен более подробный обзор, то дайте знать.❤️
UPD: пока писала вам обзор, они со скрипом, но выиграли.
И не просто так я написала про CS:GO, потому что сегодня я хочу познакомить вас с новой трансформерной моделью от Google DeepMind , и название этой модели созвучно с названием одной когда-то лучшей команды в соревновательном CS:GO — команда NaVI
Авторы NaViT подчеркнули следующую проблему, с которой сталкивается каждый инженер/исследователь компьютерного зрения при проведении экспериментов с обучением своих моделей: это выбор подходящего фиксированного размера входных изображений. Конечно, трансформерные модели более гибкие в решении данной проблемы из-за того, что изображение обрабатывается как последовательностей патчей различной длины. Поэтому Google DeepMind решили воспользоваться данным преимуществом, сделав новую модель, которая для обработки входных изображений с произвольным разрешением и соотношением сторон формирует такие последовательности во время обучения. NaViT можно применить не только для классификации изображений и видео, но и для детекции и сегментации, а также для других задач компьютерного зрения. Никаких больше лишних экспериментов
Cпойлер: опять взяли очередную хорошую идею из NLP.
Из-за ограничения количества символов в сообщение/посте у Телеграма, то читайте остальной разбор здесь. Сторис выкатили, а на развитие функциональности каналов забили!
Если нужен более подробный обзор, то дайте знать.