Короче, я наконец добралась до этой статьи, дабы понять за счет чего child-tuning дает прирост скора на реальных экспериментах 🤔
Рассказываю: чем больше модель, тем очевидно дает лучшие результаты ее промтинг. Она тупо много знает и выигрывает за счет этого. Авторы статьи задаются вопросом, почему именно за счет vanilla fine-tuning живет NLP, и можно ли дообучать ее «умнее», то есть тратя меньше ресурсов, но добиваясь результатов не хуже🤔
Начало их экспериментов положили следующее наблюдение прошлых лет: если на обучении использовалась некая умная регуляризация (L2, mixout), которая штрафует за удаление градиентов ft модели относительно pretrained версии, то такой подход оказывается эффективнее
Получается следующее: можно выделить некую дочернюю модель, в которой backprop будет проходить лишь по части параметров. Но за счет того, что мы оставим только «важные» градиенты, мы добьемся результатов не хуже, чем обучая жирную модельку
Звучит многообещающе, но возникает логичный вопрос: каким способом выделять градиенты. И тут на помощь приходят 2 подхода child- tuning f и child-tuning d
Child-tuning f: с помощью распределения Бернулли определяется маска градиентов, где 0 – градиент меньше вероятности, заданной гиперпараметром, а 1 – больше.
Child-tuning d: с помощью критерия Фишера определяется ковариация градиента log likelihood относительно параметров
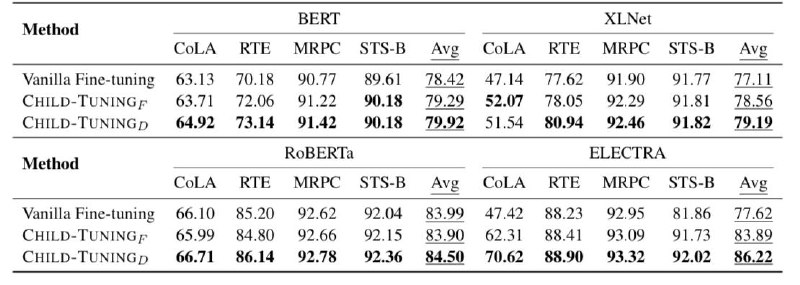
По традиции апгрейд скора метода во вложениях☺️
Рассказываю: чем больше модель, тем очевидно дает лучшие результаты ее промтинг. Она тупо много знает и выигрывает за счет этого. Авторы статьи задаются вопросом, почему именно за счет vanilla fine-tuning живет NLP, и можно ли дообучать ее «умнее», то есть тратя меньше ресурсов, но добиваясь результатов не хуже
Начало их экспериментов положили следующее наблюдение прошлых лет: если на обучении использовалась некая умная регуляризация (L2, mixout), которая штрафует за удаление градиентов ft модели относительно pretrained версии, то такой подход оказывается эффективнее
Получается следующее: можно выделить некую дочернюю модель, в которой backprop будет проходить лишь по части параметров. Но за счет того, что мы оставим только «важные» градиенты, мы добьемся результатов не хуже, чем обучая жирную модельку
Звучит многообещающе, но возникает логичный вопрос: каким способом выделять градиенты. И тут на помощь приходят 2 подхода child- tuning f и child-tuning d
Child-tuning f: с помощью распределения Бернулли определяется маска градиентов, где 0 – градиент меньше вероятности, заданной гиперпараметром, а 1 – больше.
Child-tuning d: с помощью критерия Фишера определяется ковариация градиента log likelihood относительно параметров
По традиции апгрейд скора метода во вложениях