Неклассические бустинги над деревьями (hybrid regression tree boosting)
У бустингов над деревьями есть некоторые проблемы с линейными зависимостями. Почему бы тогда не совместить бустинг, деревья и линейную регрессию?
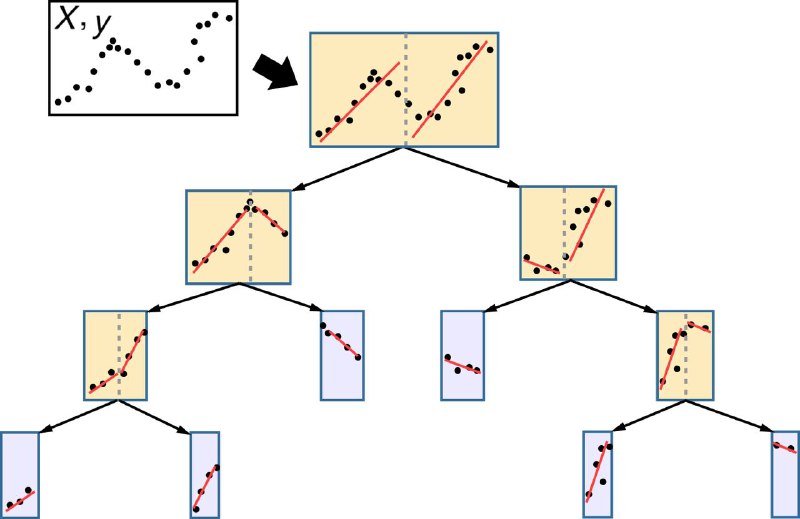
Идея такая: в классическом дереве для задачи регрессии для прогноза в каждом листе берется среднее таргетов (для rmse loss). Что если вместо простого среднего строить в листе линейную регрессию? И в качестве прогноза брать прогноз линейной регрессии
Так и возник подход hybrid regression tree (HRT) - это дерево, в каждом листе которого есть линейная регрессия. Пример работы можно посмотреть на картинке к посту. Ну и конечно это можно обобщить до бустинга
Штука прикольная, и как-то в универе мы с ребятами даже запилили код hybrid regression tree. Ни о какой оптимизации по скорости и памяти в студенческом проекте речи конечно нет, но поиграться можно
И внезапно наша репа до сих пор топ-1 по запросу ”hybryd regression tree” в гугле аж с 2 звездочками 😅
Это говорит скорее о непопулярности подхода - по метрикам чуть лучше классического lightGBM / CatBoost, но сииииильно медленнее: может работать только на небольших наборах данных до 10-100к строк. Можете, кстати, посчитать сложность алгоритма в комментариях - удивитесь 😄
UPD: В комментариях подсказали, что этот алгоритм завезли в lightGBM. Что ж, очень радует!)
#answers - ответы на вопросы из комментариев
У бустингов над деревьями есть некоторые проблемы с линейными зависимостями. Почему бы тогда не совместить бустинг, деревья и линейную регрессию?
Идея такая: в классическом дереве для задачи регрессии для прогноза в каждом листе берется среднее таргетов (для rmse loss). Что если вместо простого среднего строить в листе линейную регрессию? И в качестве прогноза брать прогноз линейной регрессии
Так и возник подход hybrid regression tree (HRT) - это дерево, в каждом листе которого есть линейная регрессия. Пример работы можно посмотреть на картинке к посту. Ну и конечно это можно обобщить до бустинга
Штука прикольная, и как-то в универе мы с ребятами даже запилили код hybrid regression tree. Ни о какой оптимизации по скорости и памяти в студенческом проекте речи конечно нет, но поиграться можно
И внезапно наша репа до сих пор топ-1 по запросу ”hybryd regression tree” в гугле аж с 2 звездочками 😅
Это говорит скорее о непопулярности подхода - по метрикам чуть лучше классического lightGBM / CatBoost, но сииииильно медленнее: может работать только на небольших наборах данных до 10-100к строк. Можете, кстати, посчитать сложность алгоритма в комментариях - удивитесь 😄
UPD: В комментариях подсказали, что этот алгоритм завезли в lightGBM. Что ж, очень радует!)
#answers - ответы на вопросы из комментариев