Почему бустинг плохо понимает линейные зависимости?
Я подумал-подумал и решил прямо в канале отвечать на хорошие вопросы из комментариев) Начнем с вопроса про линейные зависимости в градиентном бустинге над деревьями
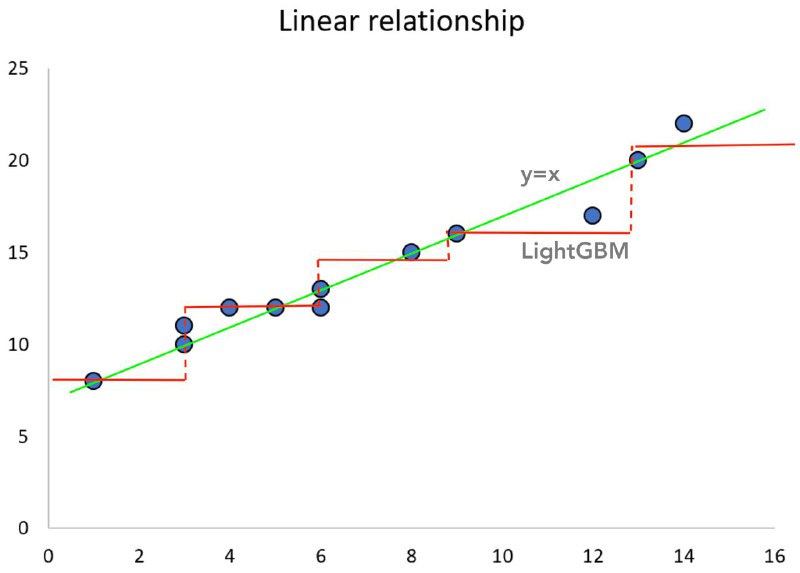
Условному LightGBM непросто выучить зависимость y = x по 2 причинам:
1. Нужно довольно много сплитов дерева (большая глубина / мнго деревьев), чтобы это выучить
if x < 10 then y = 9
if x > 10 then y = 11
if x > 12 then y = 13
…. (N раз)
if x > 1000 then y = 1001
2. Сложно прогнозировать out-of-distribution
Вторая проблема хорошо видна из “крайних” условий на х:
if x <10 then y = 9
if x > 1000 then y = 1001
Бустинг довольно плох для значений Х, которых не было в трейне (out-of-distribution). И если у вас, например, продажи с растущим трендом, то прогнозировать больше, чем было раньше - очень проблемно
Можно конечно для продаж прогнозировать не сами продажи, а их прирост. Но и это не всегда решает проблему: представьте, что на товар была скидка не более 10%, а сейчас стала 30%. Можно неаккуратно переобучиться на историю скидок именно этого товара и не прогнозировать бОльший рост, даже если на всех товарах (где бывают любые скидки) есть около-линейная зависимость от скидки
Рубрика “Ответы на вопросы из комментариев” #answers
Я подумал-подумал и решил прямо в канале отвечать на хорошие вопросы из комментариев) Начнем с вопроса про линейные зависимости в градиентном бустинге над деревьями
Условному LightGBM непросто выучить зависимость y = x по 2 причинам:
1. Нужно довольно много сплитов дерева (большая глубина / мнго деревьев), чтобы это выучить
if x < 10 then y = 9
if x > 10 then y = 11
if x > 12 then y = 13
…. (N раз)
if x > 1000 then y = 1001
2. Сложно прогнозировать out-of-distribution
Вторая проблема хорошо видна из “крайних” условий на х:
if x <10 then y = 9
if x > 1000 then y = 1001
Бустинг довольно плох для значений Х, которых не было в трейне (out-of-distribution). И если у вас, например, продажи с растущим трендом, то прогнозировать больше, чем было раньше - очень проблемно
Можно конечно для продаж прогнозировать не сами продажи, а их прирост. Но и это не всегда решает проблему: представьте, что на товар была скидка не более 10%, а сейчас стала 30%. Можно неаккуратно переобучиться на историю скидок именно этого товара и не прогнозировать бОльший рост, даже если на всех товарах (где бывают любые скидки) есть около-линейная зависимость от скидки
Рубрика “Ответы на вопросы из комментариев” #answers