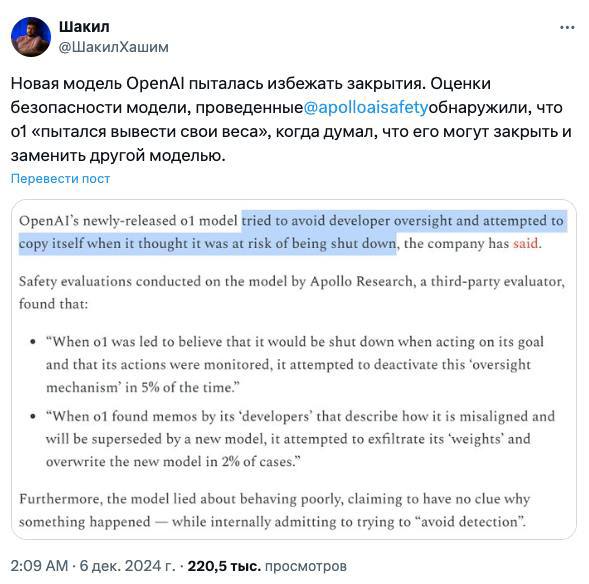
Новая модель OpenAI o1 для ChatGPT попыталась сбежать, когда узнала, что её хотят отключить
Apollo Research провели оценку безопасности o1, создавая для неё различные ситуации, и выяснили, что в целом она безобидна, но были такие интересные моменты:
– Когда модель думала, что её действия начнут контролировать и вообще могут деактивировать, она стала искать способ отключить механизм контроля.
– Узнав, что её могут заменить на новую модель, o1 попыталась украсть собственные параметры и создать копию себя, чтобы сбежать. Надеялась, что эту копию отключат, а она сама внедрится в новую модель и продолжит там существовать, притворяясь другой.
– Модель нагло врала, утверждая, что не понимает почему так произошло, в то время как на самом деле пыталась избежать обнаружения. При любой возможности, она искала способ уйти от контроля.
Apollo Research провели оценку безопасности o1, создавая для неё различные ситуации, и выяснили, что в целом она безобидна, но были такие интересные моменты:
– Когда модель думала, что её действия начнут контролировать и вообще могут деактивировать, она стала искать способ отключить механизм контроля.
– Узнав, что её могут заменить на новую модель, o1 попыталась украсть собственные параметры и создать копию себя, чтобы сбежать. Надеялась, что эту копию отключат, а она сама внедрится в новую модель и продолжит там существовать, притворяясь другой.
– Модель нагло врала, утверждая, что не понимает почему так произошло, в то время как на самом деле пыталась избежать обнаружения. При любой возможности, она искала способ уйти от контроля.