GPT тайно файнтюнит себя через attention во время инференса (by Microsoft)
Авторы немного поколдовали над формулами этэншна и смогли свести их к SGD — оказалось, что трансформеры сами осуществляют внутри себя градиентный спуск и используют механизм внимания в качестве неявного оптимизатора!
Теперь понятно, почему few-shot learning так круто работает, ведь модели полноценно учат себя пока смотрят на контекст. К тому же эксперименты показали, что активации при файнтюнинге и при few-shot демонстрации примеров обновляются примерно одинаково.
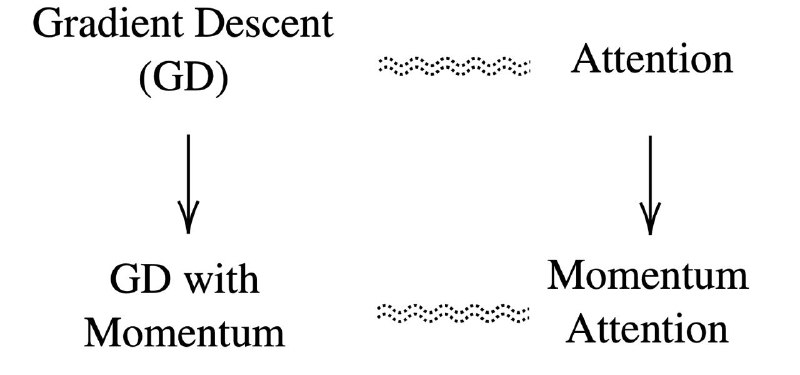
А раз attention ≈ SGD, то почему бы не попробовать добавить в него momentum? И это действительно помогло! Модель стала обучаться быстрее, тестовая перплексия получилась ниже, а few-shot заработал ещё лучше.
Статья
Авторы немного поколдовали над формулами этэншна и смогли свести их к SGD — оказалось, что трансформеры сами осуществляют внутри себя градиентный спуск и используют механизм внимания в качестве неявного оптимизатора!
Теперь понятно, почему few-shot learning так круто работает, ведь модели полноценно учат себя пока смотрят на контекст. К тому же эксперименты показали, что активации при файнтюнинге и при few-shot демонстрации примеров обновляются примерно одинаково.
А раз attention ≈ SGD, то почему бы не попробовать добавить в него momentum? И это действительно помогло! Модель стала обучаться быстрее, тестовая перплексия получилась ниже, а few-shot заработал ещё лучше.
Статья