🎞Мы сделали это: выпускаем новый бенчмарк для русского языка - TAPE!
Да-да, тот самый, самый, с которым мы ездили на EMNLP.
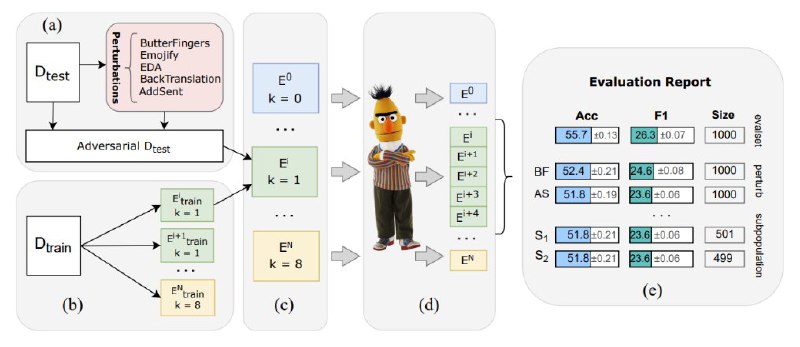
TAPE (Text Attack and Perturbation Evaluation) - это первый few-shot бенчмарк для русского языка. Он позволяет оценивать, насколько хорошо языковые модели решают задачи без дополнительного дообучения (no fine-tune here!), основываясь лишь на том, что они выучили на этапе предобучения. А чтобы было совсем интересно, для каждого датасета в TAPE есть несколько "подпорченных версий" (adversarial versions), которые позволяют оценить, насколько модель устойчива к шуму: опечатки, эмодзи, перестановки слов и т.д.
📼Итак, TAPE:
🔹оценивает модели в формате few-/zero-shot
🔹имеет отдельную библиотеку, которая аугментирует данные, внося разные изменения и пертурбации
🔹работает с фиксированными сетами примеров во few-shot оценке
🔹содержит 6 новых сложных задач, включая задачи на этику и ризонинг
🔹 отлично подходит даже для генеративных моделей
📜Теперь о датасетах в TAPE:
RuOpenBookQA и RuWorldTree: выбор правильного ответа на вопрос из нескольких вариантов (англ. multiple-choice question answering);
MultiQ: поиск правильного ответа на вопрос посредством агрегации фактологической информации из нескольких тематически связанных текстов (англ. multi-hop question answering);
CheGeKa: поиск ответа на открытый вопрос с опорой на логику и общие знания о мире (англ. open-domain question answering);
Ethics: многоаспектная оценка этических ситуаций, описанных в тексте (англ. ethical judgments);
Winograd: разрешение кореференции в текстах со сложными и неоднозначными синтаксическими связями (англ. coreference resolution или The Winograd Schema Challenge).
🤗HuggingFace c датасетами
🖥 Github бенчмарка
🖥 Библиотека RuTransform для аугментации данных
🖥 Статья (Findings of EMNLP 2022)
🎞Сайт бенчмарка
#nlp #про_nlp #emnlp
Да-да, тот самый, самый, с которым мы ездили на EMNLP.
TAPE (Text Attack and Perturbation Evaluation) - это первый few-shot бенчмарк для русского языка. Он позволяет оценивать, насколько хорошо языковые модели решают задачи без дополнительного дообучения (no fine-tune here!), основываясь лишь на том, что они выучили на этапе предобучения. А чтобы было совсем интересно, для каждого датасета в TAPE есть несколько "подпорченных версий" (adversarial versions), которые позволяют оценить, насколько модель устойчива к шуму: опечатки, эмодзи, перестановки слов и т.д.
📼Итак, TAPE:
🔹оценивает модели в формате few-/zero-shot
🔹имеет отдельную библиотеку, которая аугментирует данные, внося разные изменения и пертурбации
🔹работает с фиксированными сетами примеров во few-shot оценке
🔹содержит 6 новых сложных задач, включая задачи на этику и ризонинг
🔹 отлично подходит даже для генеративных моделей
📜Теперь о датасетах в TAPE:
RuOpenBookQA и RuWorldTree: выбор правильного ответа на вопрос из нескольких вариантов (англ. multiple-choice question answering);
MultiQ: поиск правильного ответа на вопрос посредством агрегации фактологической информации из нескольких тематически связанных текстов (англ. multi-hop question answering);
CheGeKa: поиск ответа на открытый вопрос с опорой на логику и общие знания о мире (англ. open-domain question answering);
Ethics: многоаспектная оценка этических ситуаций, описанных в тексте (англ. ethical judgments);
Winograd: разрешение кореференции в текстах со сложными и неоднозначными синтаксическими связями (англ. coreference resolution или The Winograd Schema Challenge).
🤗HuggingFace c датасетами
🎞Сайт бенчмарка
#nlp #про_nlp #emnlp