🎚 Очередной чит-лист по проектированию систем от Alex Xu (ByteByteGo) в LinkedIn. На этот раз я перевёл для вас его пост про масштабируемость, пропускную способность и доступность системы.
Нам часто говорят, что нужно проектировать сервисы высокодоступными, хорошо масштабируемыми и с высокой пропускной способностью. Но что это означает на практике?
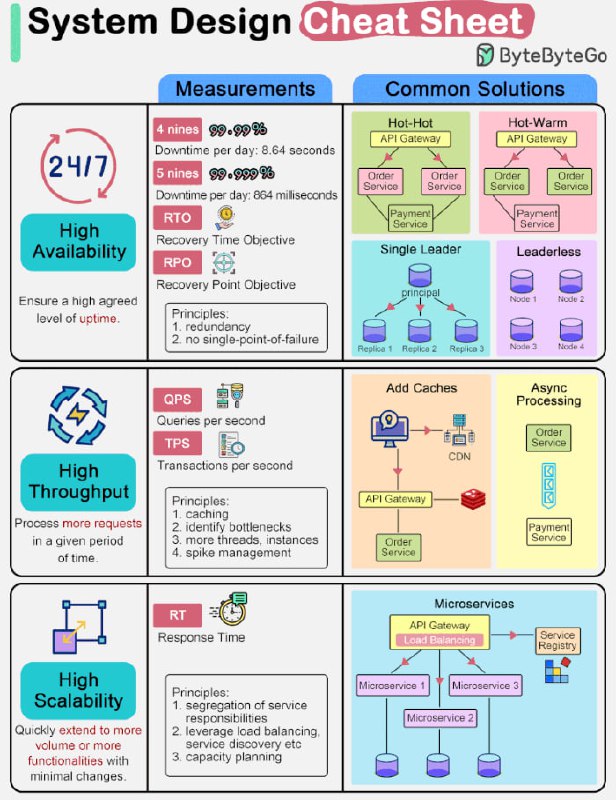
1️⃣ Высокая доступность
Это означает, что нам нужно добиться наиболее высокого аптайма (суммарное время работы системы без сбоев и отключений за определённый период времени). Обычно при проектировании проговаривается целевой показатель доступности "3 девятки" или "4 девятки". 4 девятки (аптайм 99,99%) означает, что сервис может быть недоступен только 8,64 секунды в день.
Чтобы достичь высокой доступности, мы должны использовать избыточность при проектировании системы. Есть несколько способов это сделать:
🔹 Hot-hot: два экземпляра системы (инстанса) получают одно и то же на вход и отдают одно и то же на выход для сервиса в последующий сервис. В ситуации, когда один из инстансов "упадёт", то второй сможет сразу его подменить. Т. к. оба инстанса отправляют данные в последующий сервис, то этому сервису нужно сделать так, чтобы на его стороне не было дубликатов данных.
🔹 Hot-warm: два инстанса получают одинаковые данные на вход, но только один из них (hot) отправляет исходящие данные в последующий сервис. В случае, если hot-инстанс "упал", warm-инстанс подхватывает работу и начинает слать исходящие данные в последующий сервис.
🔹 Single-leader-кластер (кластер с одним лидером): данные на вход получает только один лидер-инстанс, а потом он дублирует данные на другие экземпляры сервиса.
🔹 Leaderless-кластер (кластер без лидера): в этом типе кластера лидера нет вообще. Любая запись данных дублируется на все инстансы. Пока сумма инстансов для записи и инстансов для чтения будет больше, чем общее количество инстансов, то кластер может гарантировать согласованность данных.
2️⃣ Высокая пропускная способность
Это означает, что сервису нужно обрабатывать большое количество запросов в заданный период времени. Обычно используются метрики QPS (query per second - запросов в секунду) или TPS (transaction per second - транзакций в секунду).
Чтобы добиться высокой пропускной способности, часто используется кэширование, чтобы запрос мог обработаться без участия медленных устройств ввода-вывода, таких как базы данных и диски. Также можно увеличить количество потоков для задач, требующих интенсивных вычислений. Тем не менее, добавление слишком большого количества потоков может ухудшить производительность. В этом случае нам нужно будет найти узкие места в системе и увеличить их пропускную способность. Использование асинхроной обработки часто может эффективно изолировать "тяжеловесные" ресурсоёмкие компоненты.
3️⃣ Высокая масштабируемость
Это означает, что система может быстро и просто расширяться для обработки больших объёмов данных (горизонтальное масштабирование) или большего числа функций (вертикальная масштабируемость). Обычно смотрят на время отклика, чтобы решить, нужно ли масштабировать систему.
Нам часто говорят, что нужно проектировать сервисы высокодоступными, хорошо масштабируемыми и с высокой пропускной способностью. Но что это означает на практике?
1️⃣ Высокая доступность
Это означает, что нам нужно добиться наиболее высокого аптайма (суммарное время работы системы без сбоев и отключений за определённый период времени). Обычно при проектировании проговаривается целевой показатель доступности "3 девятки" или "4 девятки". 4 девятки (аптайм 99,99%) означает, что сервис может быть недоступен только 8,64 секунды в день.
Чтобы достичь высокой доступности, мы должны использовать избыточность при проектировании системы. Есть несколько способов это сделать:
🔹 Hot-hot: два экземпляра системы (инстанса) получают одно и то же на вход и отдают одно и то же на выход для сервиса в последующий сервис. В ситуации, когда один из инстансов "упадёт", то второй сможет сразу его подменить. Т. к. оба инстанса отправляют данные в последующий сервис, то этому сервису нужно сделать так, чтобы на его стороне не было дубликатов данных.
🔹 Hot-warm: два инстанса получают одинаковые данные на вход, но только один из них (hot) отправляет исходящие данные в последующий сервис. В случае, если hot-инстанс "упал", warm-инстанс подхватывает работу и начинает слать исходящие данные в последующий сервис.
🔹 Single-leader-кластер (кластер с одним лидером): данные на вход получает только один лидер-инстанс, а потом он дублирует данные на другие экземпляры сервиса.
🔹 Leaderless-кластер (кластер без лидера): в этом типе кластера лидера нет вообще. Любая запись данных дублируется на все инстансы. Пока сумма инстансов для записи и инстансов для чтения будет больше, чем общее количество инстансов, то кластер может гарантировать согласованность данных.
2️⃣ Высокая пропускная способность
Это означает, что сервису нужно обрабатывать большое количество запросов в заданный период времени. Обычно используются метрики QPS (query per second - запросов в секунду) или TPS (transaction per second - транзакций в секунду).
Чтобы добиться высокой пропускной способности, часто используется кэширование, чтобы запрос мог обработаться без участия медленных устройств ввода-вывода, таких как базы данных и диски. Также можно увеличить количество потоков для задач, требующих интенсивных вычислений. Тем не менее, добавление слишком большого количества потоков может ухудшить производительность. В этом случае нам нужно будет найти узкие места в системе и увеличить их пропускную способность. Использование асинхроной обработки часто может эффективно изолировать "тяжеловесные" ресурсоёмкие компоненты.
3️⃣ Высокая масштабируемость
Это означает, что система может быстро и просто расширяться для обработки больших объёмов данных (горизонтальное масштабирование) или большего числа функций (вертикальная масштабируемость). Обычно смотрят на время отклика, чтобы решить, нужно ли масштабировать систему.