🖋 Overfitting - термин с двумя интерпретациями
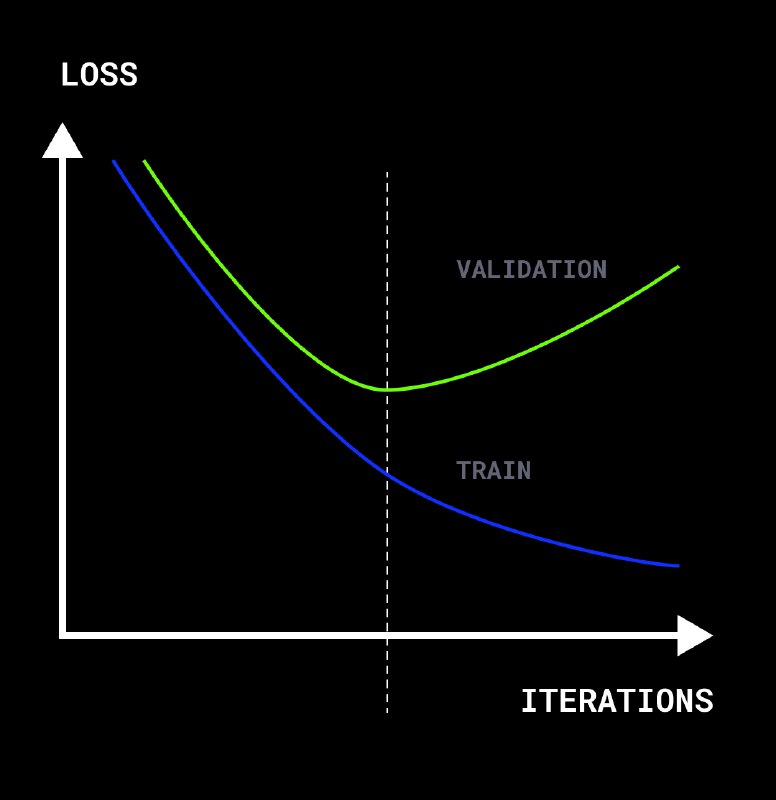
Не все явления машинного обучения имеют одно значение. Например, есть такое центральное понятие — «явление переобучения», по-английски — overfitting. Оно означает, что мы отлично работаем на тех данных, на которых обучался алгоритм, но на новых данных, пришедших к нам из жизни, мы почему-то работаем не очень хорошо.
И у явления переобучения есть как минимум два разных понимания.
1️⃣ Первое — конкретная модель с конкретными параметрами имеет низкую обобщающую способность, т.е. на обучающей выборке качество высокое, а на валидационной или тестовой выборке качество заметно ниже
2️⃣ Есть и второе. Мы можем сказать, что переобучение — это некий процесс, когда наша модель начинает слишком подстраиваться под обучающую выборку. И наступает он тогда, когда при усложнении модели качество на обучающей выборке продолжает расти, а на валидационной или тестовой — падать.
Первое определение приводит к тому, что в большинстве случаев мы имеем дело с уже переобученной моделью. Качество на обучающей выборке около 100%, а качество на валидационной выборке всегда будет существенно меньше. В частности, всегда переобученными получаются леса и градиентный бустинг над деревьями.
Если смотреть с точки зрения второго способа, то переобученным мы будем называть только тот градиентный бустинг, который при добавлении следующих деревьев становится хуже на валидационной выборке.
Не все явления машинного обучения имеют одно значение. Например, есть такое центральное понятие — «явление переобучения», по-английски — overfitting. Оно означает, что мы отлично работаем на тех данных, на которых обучался алгоритм, но на новых данных, пришедших к нам из жизни, мы почему-то работаем не очень хорошо.
И у явления переобучения есть как минимум два разных понимания.
1️⃣ Первое — конкретная модель с конкретными параметрами имеет низкую обобщающую способность, т.е. на обучающей выборке качество высокое, а на валидационной или тестовой выборке качество заметно ниже
2️⃣ Есть и второе. Мы можем сказать, что переобучение — это некий процесс, когда наша модель начинает слишком подстраиваться под обучающую выборку. И наступает он тогда, когда при усложнении модели качество на обучающей выборке продолжает расти, а на валидационной или тестовой — падать.
Первое определение приводит к тому, что в большинстве случаев мы имеем дело с уже переобученной моделью. Качество на обучающей выборке около 100%, а качество на валидационной выборке всегда будет существенно меньше. В частности, всегда переобученными получаются леса и градиентный бустинг над деревьями.
Если смотреть с точки зрения второго способа, то переобученным мы будем называть только тот градиентный бустинг, который при добавлении следующих деревьев становится хуже на валидационной выборке.