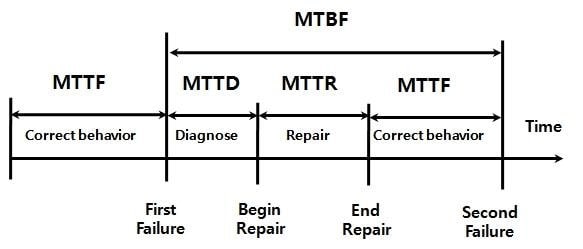
Для тех, кто занимается обеспечением надежности (
-
-
-
-
Возвращаясь к тому, что
В контейнерных инфраструктурах (
reliability) работы своих сервисов следующие метрики точно знакомы:-
MTTF - mean time to failure (среднего времени до отказа)-
MTBF - mean time between failures (среднего времени между отказами)-
MTTD - mean time to detect (когда проблема уже присутствовала, но о ней еще не было известно)-
MTTR - mean time to repair/recover/resolve/response (среднее время, необходимое на восстановление работоспособности системы после получения сигнала о сбое.)Возвращаясь к тому, что
reliability и security вещи не разделимы, то эти же метрики можно совершенно успешно использовать и в security для работы с инцидентами безопасности. Так, на пример, MTTD + MTTR = это общая продолжительность инцидента информационной безопасности.В контейнерных инфраструктурах (
Kubernetes не исключение) очень важно фиксировать инциденты ведь контейнеры/поды сущности эфемерные и часто завершаются, все унося с собой ...