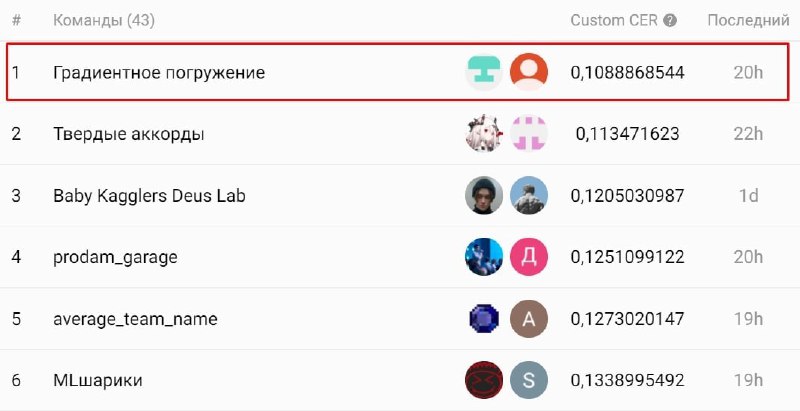
Мы на паблике - первые 🥇
Ну или почти, в любом случае, можно и нужно подвести некоторые итоги финала Олимпиады НТО по распознаванию рукописного текст в тетрадях на русском и английском.
👉 Как обычно, начнем с хорошего:
1️⃣ Заняли первое место лидерборда с самого начала соревнования. 🔥
2️⃣ Использовали кристофари, что сильно помогло вырваться вперёд за счёт объёма памяти(32гб). Разрешение картинок на входе 2160 X 3130.
3️⃣ Обучали предобученную на Digital Peter CRNN (с аугментациями и чуть более расширенной версией бейзлайна) + статистически-языковую модель(KenLM) для beam search.
4️⃣ KenLM обучали на собранном датасете заданий с текстом из ОГЭ/ЕГЭ для русского и на датасете соревнования Feedback(сочинения на англе) с кагла.
5️⃣ Использовали detectron2 с аугментациями и чуть-чуть почищенным сетом, моделька X101 - топ зоопарка на датасете COCO.
Ну или почти, в любом случае, можно и нужно подвести некоторые итоги финала Олимпиады НТО по распознаванию рукописного текст в тетрадях на русском и английском.
👉 Как обычно, начнем с хорошего:
1️⃣ Заняли первое место лидерборда с самого начала соревнования. 🔥
2️⃣ Использовали кристофари, что сильно помогло вырваться вперёд за счёт объёма памяти(32гб). Разрешение картинок на входе 2160 X 3130.
3️⃣ Обучали предобученную на Digital Peter CRNN (с аугментациями и чуть более расширенной версией бейзлайна) + статистически-языковую модель(KenLM) для beam search.
4️⃣ KenLM обучали на собранном датасете заданий с текстом из ОГЭ/ЕГЭ для русского и на датасете соревнования Feedback(сочинения на англе) с кагла.
5️⃣ Использовали detectron2 с аугментациями и чуть-чуть почищенным сетом, моделька X101 - топ зоопарка на датасете COCO.