Pre-Train Your Loss
Глубокое обучение все больше пользуется парадигмой transfer learning, при которой большие базовые (или как у нас их тут в Стенфорде называют - фундаментальные) модели дообучаются на последующих задачах.
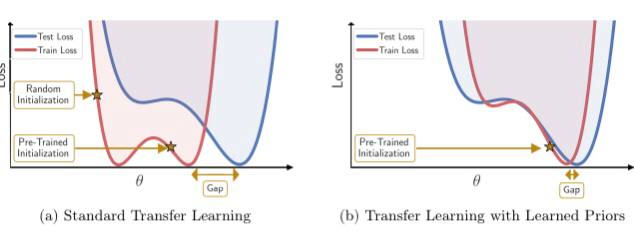
Впечатляющий коллектив авторов, под руководством Вилсона (со-автор таких проектов как loss landscape и SWA) и ЛеКуна, показывает, что можно изучить высокоинформативный posterior исходной задачи с помощью supervised или self-supervised learning, которые затем служат основой для priors, изменяющих всю поверхность потерь в последующей задаче.
Этот простой модульный подход обеспечивает значительный прирост производительности и более эффективное обучение на различных последующих задачах классификации и сегментации, выступая в качестве замены стандартных стратегий предварительного обучения.
📖 статья 🤖 код
Глубокое обучение все больше пользуется парадигмой transfer learning, при которой большие базовые (или как у нас их тут в Стенфорде называют - фундаментальные) модели дообучаются на последующих задачах.
Впечатляющий коллектив авторов, под руководством Вилсона (со-автор таких проектов как loss landscape и SWA) и ЛеКуна, показывает, что можно изучить высокоинформативный posterior исходной задачи с помощью supervised или self-supervised learning, которые затем служат основой для priors, изменяющих всю поверхность потерь в последующей задаче.
Этот простой модульный подход обеспечивает значительный прирост производительности и более эффективное обучение на различных последующих задачах классификации и сегментации, выступая в качестве замены стандартных стратегий предварительного обучения.
📖 статья 🤖 код