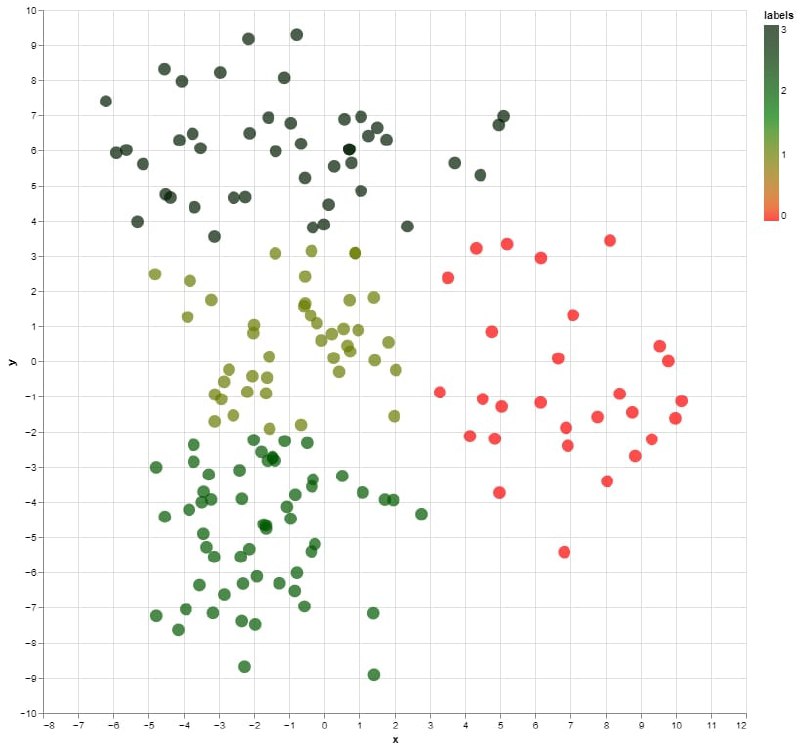
Визуализация аудитории
Сделал небольшой парсер участников канала в телеге.
Беру все доступные описания и закидываю в модель, подаю в PCA и сжимаю до вектора из 2-х элементов, ручками выбираю кол-во кластеров и строю график.
Теперь про график:
Красные - всякие ссылки на каналы
Темные - DS/ML/универы
Зеленые - словосочетания и предложения
Ну и те, что в центре - что-то между всеми остальными.
Пока делал всё это, задумался о том, сколько данных мы теряем - начиная от сжатия и заканчивая кластеризацией.
Ведь действительно, для сжатия мы подаем N-мерные вектора, которые схлопываются в 2-мерные и именно по 2-мерным мы делаем кластеризацию.
Ок, давай подавать N-мерные, в чем проблема?
Проблема в том, что тогда у кластеров не будет четкой границы и понимать график станет куда сложнее.
Этим постом я хотел вернуть нас к пониманию того, что объяснять ML довольно сложно. Почему? Потому что мы не всегда имеем полное представление о данных.
Код для визуализации
Сделал небольшой парсер участников канала в телеге.
Беру все доступные описания и закидываю в модель, подаю в PCA и сжимаю до вектора из 2-х элементов, ручками выбираю кол-во кластеров и строю график.
Теперь про график:
Красные - всякие ссылки на каналы
Темные - DS/ML/универы
Зеленые - словосочетания и предложения
Ну и те, что в центре - что-то между всеми остальными.
Пока делал всё это, задумался о том, сколько данных мы теряем - начиная от сжатия и заканчивая кластеризацией.
Ведь действительно, для сжатия мы подаем N-мерные вектора, которые схлопываются в 2-мерные и именно по 2-мерным мы делаем кластеризацию.
Ок, давай подавать N-мерные, в чем проблема?
Проблема в том, что тогда у кластеров не будет четкой границы и понимать график станет куда сложнее.
Этим постом я хотел вернуть нас к пониманию того, что объяснять ML довольно сложно. Почему? Потому что мы не всегда имеем полное представление о данных.
Код для визуализации