Store Forwarding penalties
Представьте вы пишете по указателю данные. Далее по этому указателю или где-то рядом вы читаете эти данные. Современные процессоры нынче очень хитрые и могут не читать память при такой инструкции. Это называется «store-to-load forwarding» и ускоряет программы, поскольку load инструкции не нужно ждать, пока данные будут записаны в кэш, а затем снова считываться. Пример такой последовательности очень простой:
Процессоры могут в регистр %eax сразу писать из регистра %xmm0 не дожидаясь пока в память будет что-то записано. Там есть всякие пенальти, если данные поменялись в другом треде походу этой оптимизации, но речь немного не о них сегодня.
Так получилось, что мы нашли какие-то безумные штрафы на Intel и Arm. Например
Intel:
1. Загрузить 2 байта
2. Прочитать второй следующей инструкцией
Работает в 2-3 раза дольше, чем
1. Загрузить 2 байта
2. Прочитать первый
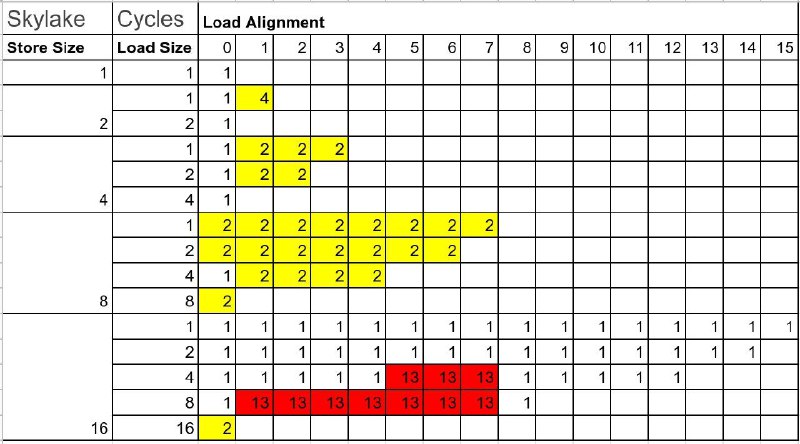
Решил сделать бенчмарк, который загружает Х байт (X = 2,4,8,16), читает Y байт (Y = 1,2,4,8,16) по оффсету Z (Z = 0..15) с условием, что Y + Z <= X. Получились цифры как на картинках для AMD Rome, Intel Skylake и Graviton 2.
Выводы
1. AMD всегда хорошо применяет эту оптимизацию
2. Intel плохо работает, если грузить 2-й байт при загрузке 2. Также плохо, если при загрузке 16 байт мы читаем 4/8, и они переходят границу в 8 байт (размер регистра, походу)
3. Arm работают плохо, кроме выравнивания по 0, reg_size/2.
Это важно всяким small string optimization, rope/cord, compressors, потому что они используют стек как данные и одновременно как идентификаторы, а большие или маленькие они.
Решил сделать бенчмарк, на Rust. https://github.com/danlark1/store_forwarding
Agner Fog писал про это, но мало.
Если поменять layout absl::Cord на обратный, Arm ускоряется, по табличке грузить 1 байт по оффсету 0 лучше, чем по 15 :)
Представьте вы пишете по указателю данные. Далее по этому указателю или где-то рядом вы читаете эти данные. Современные процессоры нынче очень хитрые и могут не читать память при такой инструкции. Это называется «store-to-load forwarding» и ускоряет программы, поскольку load инструкции не нужно ждать, пока данные будут записаны в кэш, а затем снова считываться. Пример такой последовательности очень простой:
movaps %xmm0, (%rsp) # Сохраняем 16 байт по адресу
mov 2(%rsp), %eax # Читаем 4 байта с адреса +2
Процессоры могут в регистр %eax сразу писать из регистра %xmm0 не дожидаясь пока в память будет что-то записано. Там есть всякие пенальти, если данные поменялись в другом треде походу этой оптимизации, но речь немного не о них сегодня.
Так получилось, что мы нашли какие-то безумные штрафы на Intel и Arm. Например
Intel:
1. Загрузить 2 байта
write_unaligned<2>(ptr)2. Прочитать второй следующей инструкцией
read_unaligned<1>(ptr + 1)Работает в 2-3 раза дольше, чем
1. Загрузить 2 байта
write_unaligned<2>(ptr)2. Прочитать первый
read_unaligned<1>(ptr)Решил сделать бенчмарк, который загружает Х байт (X = 2,4,8,16), читает Y байт (Y = 1,2,4,8,16) по оффсету Z (Z = 0..15) с условием, что Y + Z <= X. Получились цифры как на картинках для AMD Rome, Intel Skylake и Graviton 2.
Выводы
1. AMD всегда хорошо применяет эту оптимизацию
2. Intel плохо работает, если грузить 2-й байт при загрузке 2. Также плохо, если при загрузке 16 байт мы читаем 4/8, и они переходят границу в 8 байт (размер регистра, походу)
3. Arm работают плохо, кроме выравнивания по 0, reg_size/2.
Это важно всяким small string optimization, rope/cord, compressors, потому что они используют стек как данные и одновременно как идентификаторы, а большие или маленькие они.
Решил сделать бенчмарк, на Rust. https://github.com/danlark1/store_forwarding
Agner Fog писал про это, но мало.
Если поменять layout absl::Cord на обратный, Arm ускоряется, по табличке грузить 1 байт по оффсету 0 лучше, чем по 15 :)