Test of Time: A Benchmark for Evaluating LLMs on Temporal Reasoning
Новый день, новая статья. На этот раз – бенчмарк. Те, кто трогал руками ЛЛМки знают, что со временем у них большие проблемы – всё-таки, модели текстовые, и не очень понимают, как это наше время вообще работает.🤤
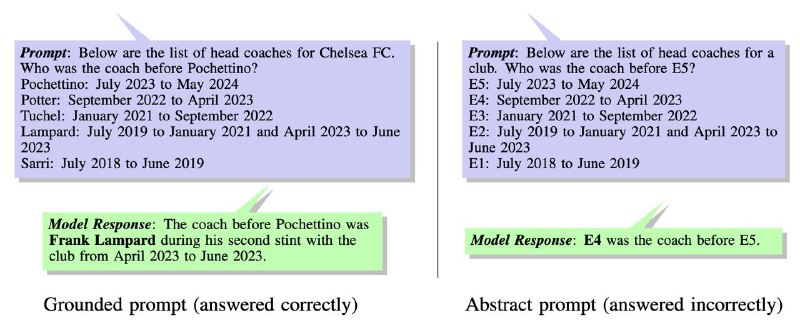
Существует несколько работ, которые меряют способности ЛЛМок рассуждать во времени на каких-нибудь реальных фактах (чаще всего из Wikidata), но так мы не можем понять, откуда пришёл правильный ответ – из памяти или при помощи рассуждений. Пример на картинке выше – ЛЛМка корректно отвечает про футбольного тренера, но с треском проваливается, если в той же задаче заменить сущности на анонимизированные айдишники.
На нашем бенчмарке Gemini 1.5 Pro обошёл GPT-4 почти во всех категориях. Может, модель всё-таки хорошая?🧐
Новый день, новая статья. На этот раз – бенчмарк. Те, кто трогал руками ЛЛМки знают, что со временем у них большие проблемы – всё-таки, модели текстовые, и не очень понимают, как это наше время вообще работает.
Существует несколько работ, которые меряют способности ЛЛМок рассуждать во времени на каких-нибудь реальных фактах (чаще всего из Wikidata), но так мы не можем понять, откуда пришёл правильный ответ – из памяти или при помощи рассуждений. Пример на картинке выше – ЛЛМка корректно отвечает про футбольного тренера, но с треском проваливается, если в той же задаче заменить сущности на анонимизированные айдишники.
На нашем бенчмарке Gemini 1.5 Pro обошёл GPT-4 почти во всех категориях. Может, модель всё-таки хорошая?