G-RAG: готовим графы знаний правильно
Вторая статья, вышедшая на той неделе – про retrieval-augmented generation (RAG). Конечно же, со вкусом графов – куда ж без них?
RAG – это такой лейкопластырь, которым мы залепливаем проблему контекста в языковых моделях. Поиск мы умеем делать довольно неплохо, поэтому давайте-ка прикрутим поиск к LLMкам и будем всем счастье – ну, то есть релевантные ответы, актуальная информация, вот это вот всё.
При этом всём, information retrieval (IR), заточенный на людей, для LLMок подойдёт как минимум неидеально: люди читают первые пару заголовков, а LLMки могут прожевать десяток-другой статей (если не Gemini 1.5 с миллионой длиной контекста, конечно).
В IR популярен подход с реранкингом, когда мы простой моделью достаём какое-то количество наиболее релевантных документов, и потом более сложной моделью их ранжируем заново. В нашем случае, хочется, чтобы LLMка увидела разнообразные факты про запрос юзера в наиболее релевантных документах. С этим нам помогут графы знаний.
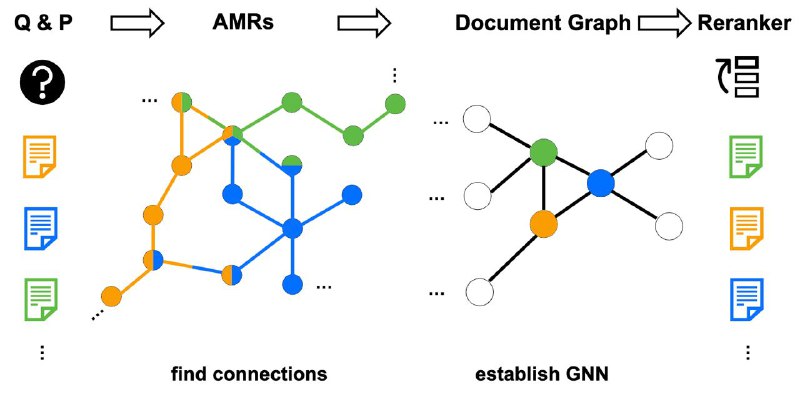
Тут нужно лирическое отступление на тему графов знаний. Я эту дедовскую👴 идею про идеально точное и полное описание сущностей отрицаю всей душой и сердцем. Ни у кого в мире не получилось построить корректно работающий граф знаний, и полагаться на одну статическую структуру для такой динамической задачи, как вопросы в свободной форме – тотальный харам. Поэтому вместо статического графа у нас динамический, который мы на этапе запроса строим по документам, которые наш ретривер вытащил на первом этапе. Это можно делать очень быстро, потому что графы по каждому документу мы можем посчитать заранее, а на этапе запроса их слепить вместе. ☺️
Этот граф мы преобразуем в граф над документами, и уже на этом графе делаем быстрый инференс графовой сетки, которая и выберет финальные документы для LLMки. Получился такой прототип для LLM-поисковика. Получившийся пайплайн выбивает существенно выше по бенчмаркам, чем существующие решения, особенно плохи чистые LLMки без RAGов. Главное в этих делах – не переесть камней.
Вторая статья, вышедшая на той неделе – про retrieval-augmented generation (RAG). Конечно же, со вкусом графов – куда ж без них?
RAG – это такой лейкопластырь, которым мы залепливаем проблему контекста в языковых моделях. Поиск мы умеем делать довольно неплохо, поэтому давайте-ка прикрутим поиск к LLMкам и будем всем счастье – ну, то есть релевантные ответы, актуальная информация, вот это вот всё.
При этом всём, information retrieval (IR), заточенный на людей, для LLMок подойдёт как минимум неидеально: люди читают первые пару заголовков, а LLMки могут прожевать десяток-другой статей (если не Gemini 1.5 с миллионой длиной контекста, конечно).
В IR популярен подход с реранкингом, когда мы простой моделью достаём какое-то количество наиболее релевантных документов, и потом более сложной моделью их ранжируем заново. В нашем случае, хочется, чтобы LLMка увидела разнообразные факты про запрос юзера в наиболее релевантных документах. С этим нам помогут графы знаний.
Тут нужно лирическое отступление на тему графов знаний. Я эту дедовскую
Этот граф мы преобразуем в граф над документами, и уже на этом графе делаем быстрый инференс графовой сетки, которая и выберет финальные документы для LLMки. Получился такой прототип для LLM-поисковика. Получившийся пайплайн выбивает существенно выше по бенчмаркам, чем существующие решения, особенно плохи чистые LLMки без RAGов. Главное в этих делах – не переесть камней.