Let Your Graph Do the Talking: Encoding Structured Data for LLMs
[arXiv]
Что мы делаем в 2024? Правильно, засовываем всё, что плохо лежит🗑 , в большие языковые модели. У нас в команде плохо лежат графы, так что в нашей новой статье они отправляются напрямую в PaLM2. 👮♂️
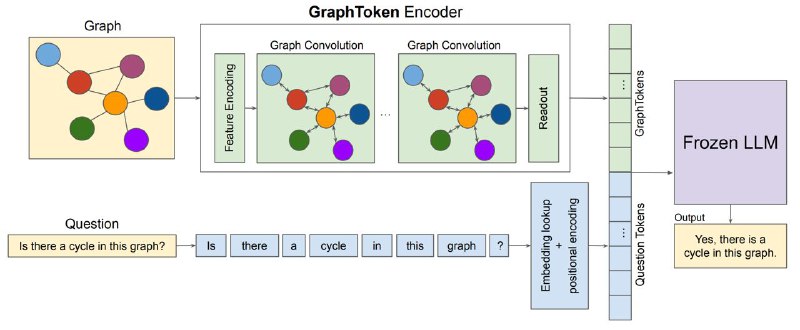
Конечно, граф нужно как-то закодировать. У коллег была статья на ICLR'24 (или будет? конференция-то будет в мае), где граф трансформируют в текст простыми способами: как список вершин и рёбер. Вместо этого мы бахнули графовую нейросетку, которая трансформирует граф в набор токенов, которые кормятся LLMке. Поскольку нам хотелось полностью погрузиться в LLM-безумие, напрямую от задачи графовая сетка градиенты не получает – только через языковую модель. Назвали модель GraphToken.👌
Поскольку мы работаем с графами, мы можем сгенерировать их все. На 8 вершинах существует 11117 связных графов, вот на них мы и тестировались. Тестсет – так уж на все точки пространства – чего мелочиться.✨
В статье мы показываем, что GraphToken умудряется генерализоваться как in-distribution с 1000 тренировочных примеров, так и out-of-distribution – на новые задачи, очень слабо связанные с предыдущими.
P.S. в названии – отсылка к песне Aerosmith.😎
[arXiv]
Что мы делаем в 2024? Правильно, засовываем всё, что плохо лежит
Конечно, граф нужно как-то закодировать. У коллег была статья на ICLR'24 (или будет? конференция-то будет в мае), где граф трансформируют в текст простыми способами: как список вершин и рёбер. Вместо этого мы бахнули графовую нейросетку, которая трансформирует граф в набор токенов, которые кормятся LLMке. Поскольку нам хотелось полностью погрузиться в LLM-безумие, напрямую от задачи графовая сетка градиенты не получает – только через языковую модель. Назвали модель GraphToken.
Поскольку мы работаем с графами, мы можем сгенерировать их все. На 8 вершинах существует 11117 связных графов, вот на них мы и тестировались. Тестсет – так уж на все точки пространства – чего мелочиться.
В статье мы показываем, что GraphToken умудряется генерализоваться как in-distribution с 1000 тренировочных примеров, так и out-of-distribution – на новые задачи, очень слабо связанные с предыдущими.
P.S. в названии – отсылка к песне Aerosmith.