На днях вышла интересная статья Vision Transformers Need Registers.
Vision Transformers (ViT) – одна из основных современных архитектур для больших vision-моделей. В отличие от счёрточных нейросетей, она отлично model-параллелится, так что получается эффективно тренировать большие модели, которые хорошо работают на практике.🥁
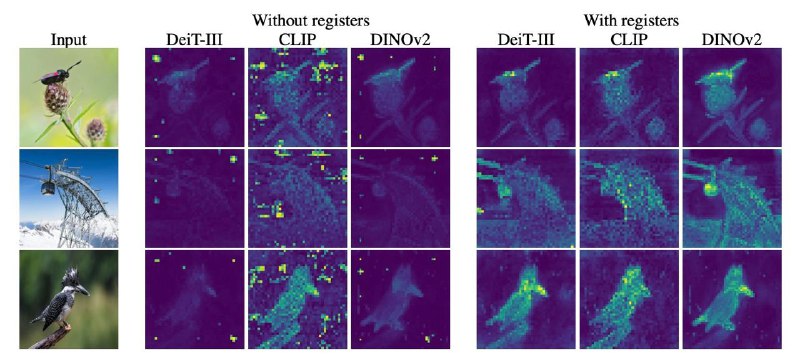
Проблема в том, что на attention масках получаются какие-то непонятные артефакты (см. картинку) в виде пикселей с очень высокими коэффициентами. Авторы статьи решили почесать репу и разобраться, какую функцию они выполняют и как от них избавиться.🧐
Оказалось, что трансформеры таким образом передают информацию между слоями, и можно это вылечить специальными токенами, которые не будут использоваться для финальной агрегации в эмбеддинг, но для них всё ещё будут учиться attention слои. Это помогло снизить проблему коммуникации и очиститьчакры attention маски.
Мне кажется, хороший пример научного подхода ко всей этой нашей машинлёрнинговой алхимии – авторы нашли странный феномен в моделях, выяснили, как он работает, пофиксили, получили прирост на бенчмарках.📈
Vision Transformers (ViT) – одна из основных современных архитектур для больших vision-моделей. В отличие от счёрточных нейросетей, она отлично model-параллелится, так что получается эффективно тренировать большие модели, которые хорошо работают на практике.
Проблема в том, что на attention масках получаются какие-то непонятные артефакты (см. картинку) в виде пикселей с очень высокими коэффициентами. Авторы статьи решили почесать репу и разобраться, какую функцию они выполняют и как от них избавиться.
Оказалось, что трансформеры таким образом передают информацию между слоями, и можно это вылечить специальными токенами, которые не будут использоваться для финальной агрегации в эмбеддинг, но для них всё ещё будут учиться attention слои. Это помогло снизить проблему коммуникации и очистить
Мне кажется, хороший пример научного подхода ко всей этой нашей машинлёрнинговой алхимии – авторы нашли странный феномен в моделях, выяснили, как он работает, пофиксили, получили прирост на бенчмарках.