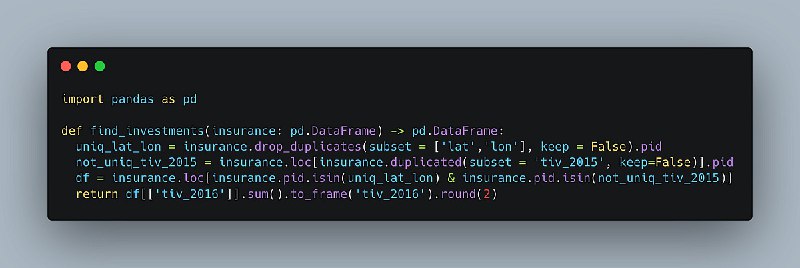
Решение вчерашней задачи
Самый простой способ — создать 2 критерия, которые позже будут использоваться в .isin():
Это делается для того, чтобы мы удалили все строки, в которых lat и lon не уникальны (keep = False гарантирует, что мы не оставим ни одного дублированного экземпляра, как это обычно происходит) - оставьте только столбец pid:
Insurance.drop_duulates(subset = ['lat','lon'], Keep = False).pid
Та же логика, но на этот раз нам нужно дублировать:
not_uniq_tiv_2015 = Insurance.loc[insurance.duulated(subset = 'tiv_2015', Keep=False)].pid
После этого просто возвращаем сумму тех tiv_2016, которые остались после фильтрации по двум созданным ранее критериям.
Самый простой способ — создать 2 критерия, которые позже будут использоваться в .isin():
Это делается для того, чтобы мы удалили все строки, в которых lat и lon не уникальны (keep = False гарантирует, что мы не оставим ни одного дублированного экземпляра, как это обычно происходит) - оставьте только столбец pid:
Insurance.drop_duulates(subset = ['lat','lon'], Keep = False).pid
Та же логика, но на этот раз нам нужно дублировать:
not_uniq_tiv_2015 = Insurance.loc[insurance.duulated(subset = 'tiv_2015', Keep=False)].pid
После этого просто возвращаем сумму тех tiv_2016, которые остались после фильтрации по двум созданным ранее критериям.