#nlp #transformers
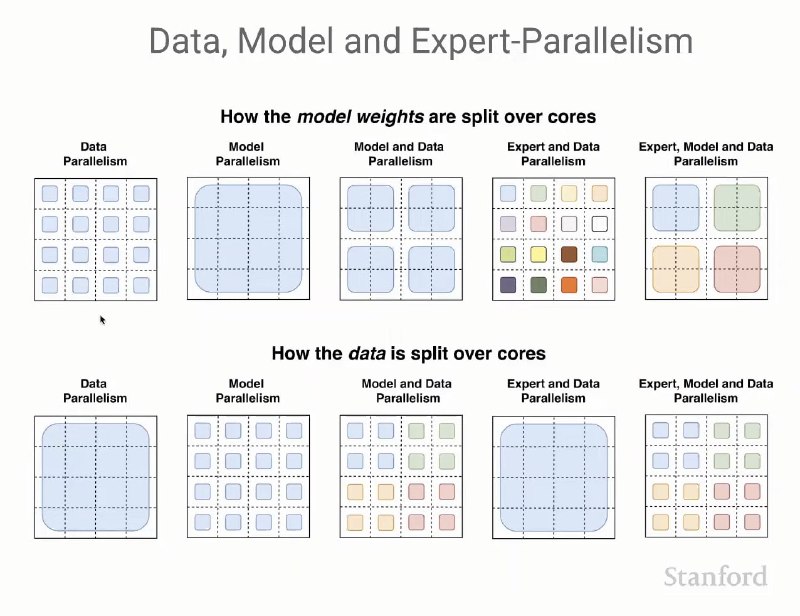
Про параллелизм
Красивый слайд из курса CS25. В последних двух колонках у нас sparse модели (MoE). Одним цветом обозначены одни и те же копии данных.
〰️ Зачем?
При масштабировании архитектуры и тренировочных данных можно упереться в ограничения по памяти/времени. Для параллельного обучения на нескольких устройствах и приходится что-то партиционировать — либо данные, либо модель, либо все вместе.
Про параллелизм
Красивый слайд из курса CS25. В последних двух колонках у нас sparse модели (MoE). Одним цветом обозначены одни и те же копии данных.
〰️ Зачем?
При масштабировании архитектуры и тренировочных данных можно упереться в ограничения по памяти/времени. Для параллельного обучения на нескольких устройствах и приходится что-то партиционировать — либо данные, либо модель, либо все вместе.