#ml #prod
🔺 ML System Design
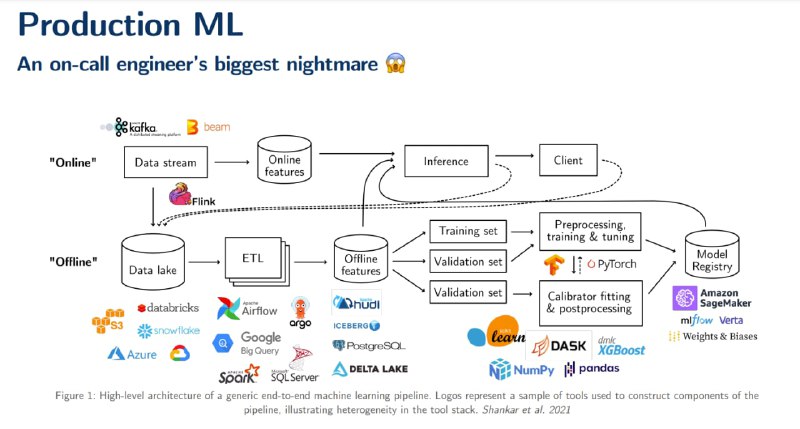
Материалы по внешней стороне машинного обучения (за внутреннюю считаем research / исследования) — проектирование того, как это все будет работать, поддерживаться и обновляться (system design).
Тема важная и начать в нее погружаться можно из актуального курса Стэнфорда cs 329s (содержание курса). Все это похоже на системное программирование, только в контексте ML. Сами лекции в виде текста, есть слайды и пара ноутбуков. Лекции прикольные, можно читать как книжку. Сам курс не очень длинный, так что будут шансы пройти до конца 😁.
👉 Лекции и TLDR;
1️⃣ Отличия ML для продакшена. tldr; Данные — сырые и меняются во времени. Приоритеты — быстрый инференс, важна интерпретируемость. Много заказчиков и требований от них.
2️⃣ Основы проектирования. tldr; Понимаем проблему (нужен ли тут вообще ML?). Источники и формат данных. ETL (процессинг и хранение данных).
3️⃣ Тренировочные данные. tldr; Тут довольно понятная тема — что делать с сырыми данными, как собрать из них хороший датасет, нехватка разметки, active learning и т.д.
4️⃣ Feature Engineering. tldr; Данные есть, как будем подавать их в модель? Аугментации (делаем данные разнообразней), придумываем новые признаки. И внезапно про позиционные эмбеддинги.
5️⃣ Model Development. tldr; Six tips for model selection. Важная мысль — не надо сразу брать SOTA, топовый результат на статическом датасете не обязательно будет лучше для вас, начните с простого. kaggle хаки/подходы — bagging, boosting, stacking.
6️⃣ Распределенное обучение и оценка модели. tldr; Про обучение на кластере и виды параллелизма. Сделай бейзлайн (рандомный, эвристики, человеческий, готовые решения). Советы по оценке моделей.
7️⃣ Деплой модели. tldr; Онлайн / оффлайн предсказания. Оптимизация модели — дистилляция, прунинг, квантизация. ML в облаке.
8️⃣ Мониторинг и дрифт данных. tldr; Хьюстон, у нас дрифт данных. Про feedback loop. Различные виды дрифта (covariate, label, concept drifts). Observability — собирай метрики, чтобы понять, что пошло не так.
🔺 ML System Design
Материалы по внешней стороне машинного обучения (за внутреннюю считаем research / исследования) — проектирование того, как это все будет работать, поддерживаться и обновляться (system design).
Тема важная и начать в нее погружаться можно из актуального курса Стэнфорда cs 329s (содержание курса). Все это похоже на системное программирование, только в контексте ML. Сами лекции в виде текста, есть слайды и пара ноутбуков. Лекции прикольные, можно читать как книжку. Сам курс не очень длинный, так что будут шансы пройти до конца 😁.
👉 Лекции и TLDR;
1️⃣ Отличия ML для продакшена. tldr; Данные — сырые и меняются во времени. Приоритеты — быстрый инференс, важна интерпретируемость. Много заказчиков и требований от них.
2️⃣ Основы проектирования. tldr; Понимаем проблему (нужен ли тут вообще ML?). Источники и формат данных. ETL (процессинг и хранение данных).
3️⃣ Тренировочные данные. tldr; Тут довольно понятная тема — что делать с сырыми данными, как собрать из них хороший датасет, нехватка разметки, active learning и т.д.
4️⃣ Feature Engineering. tldr; Данные есть, как будем подавать их в модель? Аугментации (делаем данные разнообразней), придумываем новые признаки. И внезапно про позиционные эмбеддинги.
5️⃣ Model Development. tldr; Six tips for model selection. Важная мысль — не надо сразу брать SOTA, топовый результат на статическом датасете не обязательно будет лучше для вас, начните с простого. kaggle хаки/подходы — bagging, boosting, stacking.
6️⃣ Распределенное обучение и оценка модели. tldr; Про обучение на кластере и виды параллелизма. Сделай бейзлайн (рандомный, эвристики, человеческий, готовые решения). Советы по оценке моделей.
7️⃣ Деплой модели. tldr; Онлайн / оффлайн предсказания. Оптимизация модели — дистилляция, прунинг, квантизация. ML в облаке.
8️⃣ Мониторинг и дрифт данных. tldr; Хьюстон, у нас дрифт данных. Про feedback loop. Различные виды дрифта (covariate, label, concept drifts). Observability — собирай метрики, чтобы понять, что пошло не так.