🌗 RuLeanALBERT
Коллеги из Яндекса выложили вторую языковую модель в open source и на этот раз все смогут её запустить.
Назвали модель RuLeanALBERT, так как в ней использовали идею расшаривания весов между слоями из оригинальной статьи ALBERT (A Lite BERT). Такой прием на порядок понижает вес модели (пишет про уменьшение в 32 раза). Модель обучали с нуля, поэтому применили другие улучшения типа PreNorm и GEGLU активаций. Обучали как MLM (masked language model).
〰️ Зачем?
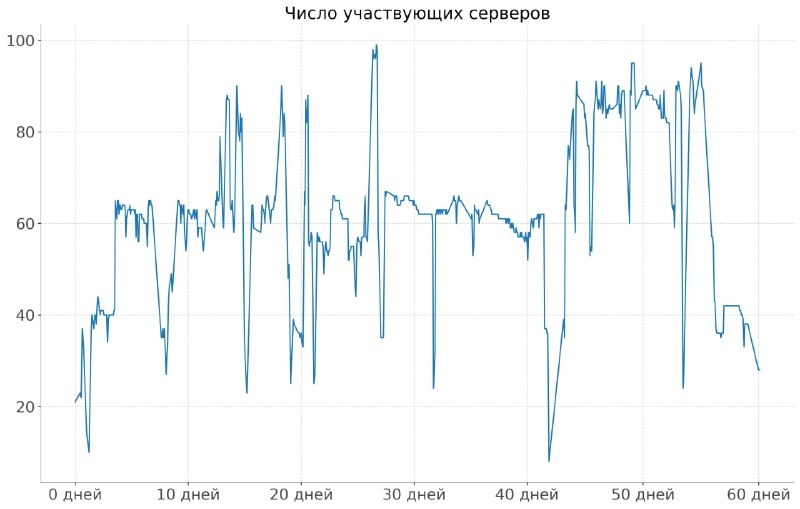
Этот кейс скорее не про архитектуру и качество модели, а про то, что ее получилось обучить на нестабильном железе. Это когда вы не бронируете себе N карт на кластере, а имеете разнородную инфраструктуру, причем текущие карты могут отваливаться, а новые подключаться (что видно на картинке). Хороший кейс, подробнее про него написали на хабре.
Код для обучения, к слову, тоже выложили.
Статья | GitHub
Коллеги из Яндекса выложили вторую языковую модель в open source и на этот раз все смогут её запустить.
Назвали модель RuLeanALBERT, так как в ней использовали идею расшаривания весов между слоями из оригинальной статьи ALBERT (A Lite BERT). Такой прием на порядок понижает вес модели (пишет про уменьшение в 32 раза). Модель обучали с нуля, поэтому применили другие улучшения типа PreNorm и GEGLU активаций. Обучали как MLM (masked language model).
〰️ Зачем?
Этот кейс скорее не про архитектуру и качество модели, а про то, что ее получилось обучить на нестабильном железе. Это когда вы не бронируете себе N карт на кластере, а имеете разнородную инфраструктуру, причем текущие карты могут отваливаться, а новые подключаться (что видно на картинке). Хороший кейс, подробнее про него написали на хабре.
Код для обучения, к слову, тоже выложили.
Статья | GitHub