#nlp #big #optimization
LLM.int8() → Слон в colab'е
⚡️В transformers добавили новый механизим квантизации (приведения весов к int8) без потери качества при инференсе.
Evaluation сделали на OPT-175B, Bloom 176B, T5-11B и T5-3B. На бенчмарках сжатые модели показали отсутствие деградации по качеству. По скорости инференса Bloom-int8 стал на 15-23% медленнее.
〰️ Зачем?
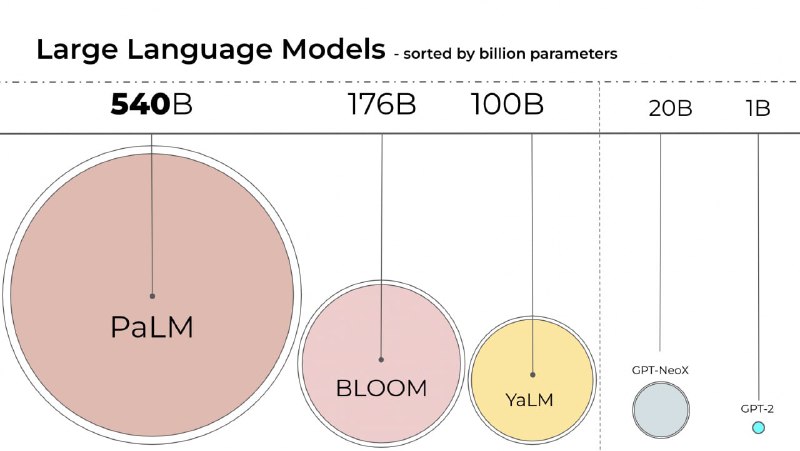
Чем больше модель, тем больше нужно вычислительных ресурсов, чтобы ее запустить (вспомните про YaLM 100B). Наиболее точные значения весов хранятся в FP32 (4 байта на число → 3B параметров ≈ 11Gb). Соответственно int8 занимает в 4 раза меньше (3B параметров ≈ 2.8Gb). В качестве примера авторы дают colab, в котором запускают модель T5 на 11B (42Gb FP32) весов.
Но ведь мы и раньше умели квантизавать, скажете вы. Потеря точности растет с увеличением модели. 🤗 определили, что обычная квантизация не годится для трансформеров больше чем 6B параметров (пишут об этом в статье).
👉 Сделан еще один шаг по укрощению больших нейросетей (всплывает аналогия со статуями Клодта, надо бы порисовать на эту тему).
Пост | Статья | Colab
LLM.int8() → Слон в colab'е
⚡️В transformers добавили новый механизим квантизации (приведения весов к int8) без потери качества при инференсе.
Evaluation сделали на OPT-175B, Bloom 176B, T5-11B и T5-3B. На бенчмарках сжатые модели показали отсутствие деградации по качеству. По скорости инференса Bloom-int8 стал на 15-23% медленнее.
〰️ Зачем?
Чем больше модель, тем больше нужно вычислительных ресурсов, чтобы ее запустить (вспомните про YaLM 100B). Наиболее точные значения весов хранятся в FP32 (4 байта на число → 3B параметров ≈ 11Gb). Соответственно int8 занимает в 4 раза меньше (3B параметров ≈ 2.8Gb). В качестве примера авторы дают colab, в котором запускают модель T5 на 11B (42Gb FP32) весов.
Но ведь мы и раньше умели квантизавать, скажете вы. Потеря точности растет с увеличением модели. 🤗 определили, что обычная квантизация не годится для трансформеров больше чем 6B параметров (пишут об этом в статье).
👉 Сделан еще один шаг по укрощению больших нейросетей (всплывает аналогия со статуями Клодта, надо бы порисовать на эту тему).
Пост | Статья | Colab