PolyViT: Co-training Vision Transformers on Images, Videos and Audio
Можно ли обучить один трансформер, который сможет обрабатывать множество модальностей и наборов данных, шэря при этом почти все обучаемые параметры?
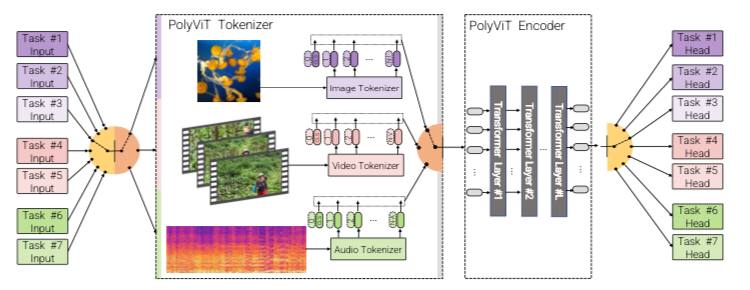
Оказалось что да. Тут выкатили PolyViT - модель, обученную на изображениях, аудио и видео. Совместное обучение различным задачам на одной модальности позволяет повысить точность каждой отдельной задачи и достичь SOTA на 5 стандартных наборах данных для классификации видео и аудио. Совместное обучение PolyViT на нескольких модальностях и задачах приводит к тому, что модель становится еще более эффективной по параметрам и обучается представлениям, которые обобщаются в различных областях.
📎 Статья
#multimodal #audio #video #images #transformer
Можно ли обучить один трансформер, который сможет обрабатывать множество модальностей и наборов данных, шэря при этом почти все обучаемые параметры?
Оказалось что да. Тут выкатили PolyViT - модель, обученную на изображениях, аудио и видео. Совместное обучение различным задачам на одной модальности позволяет повысить точность каждой отдельной задачи и достичь SOTA на 5 стандартных наборах данных для классификации видео и аудио. Совместное обучение PolyViT на нескольких модальностях и задачах приводит к тому, что модель становится еще более эффективной по параметрам и обучается представлениям, которые обобщаются в различных областях.
📎 Статья
#multimodal #audio #video #images #transformer