Эффективное обучение визуальных трансформеров на небольших наборах данных
Визуальные трансформеры (ViT) уже почти сравнялись по популярности со сверточными сетями (CNN). Однако, ViT требуется намного больше данных, чем CNN.
В статье анализируются различные ViT, сравнивается их устойчивость в режиме малого набора данных для обучения, и демонстрируется, что, несмотря на сопоставимую точность при обучении на ImageNet, их производительность на меньших наборах данных может значительно отличаться.
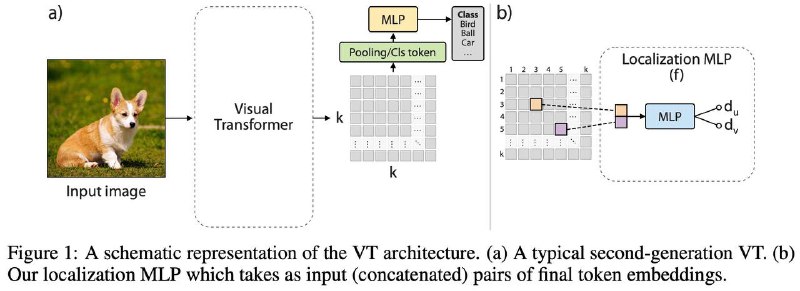
Авторы предлагают self-supervised задачу, которая может извлекать дополнительную информацию из изображений с незначительными вычислительными затратами. Эта задача побуждает ViT изучать пространственные отношения внутри изображения и делает обучение ViT гораздо более надежным в условиях нехватки обучающих данных. Задача используется совместно с supervised обучением и не зависит от конкретных архитектурных решений. Этот метод помогает улучшить конечную точность ViT.
📎 Статья
🖥 Код
#transformer #selfSupervised #images
Визуальные трансформеры (ViT) уже почти сравнялись по популярности со сверточными сетями (CNN). Однако, ViT требуется намного больше данных, чем CNN.
В статье анализируются различные ViT, сравнивается их устойчивость в режиме малого набора данных для обучения, и демонстрируется, что, несмотря на сопоставимую точность при обучении на ImageNet, их производительность на меньших наборах данных может значительно отличаться.
Авторы предлагают self-supervised задачу, которая может извлекать дополнительную информацию из изображений с незначительными вычислительными затратами. Эта задача побуждает ViT изучать пространственные отношения внутри изображения и делает обучение ViT гораздо более надежным в условиях нехватки обучающих данных. Задача используется совместно с supervised обучением и не зависит от конкретных архитектурных решений. Этот метод помогает улучшить конечную точность ViT.
📎 Статья
🖥 Код
#transformer #selfSupervised #images