🔥Куда уж меньше?
BitNet: Scaling 1-bit Transformers for Large Language Models
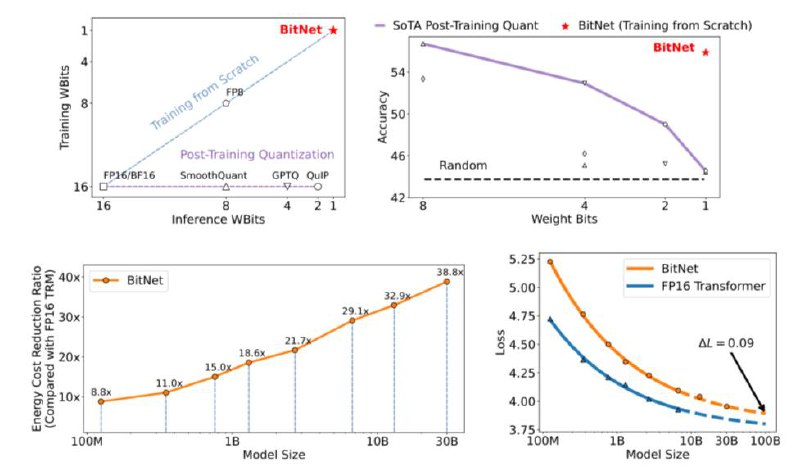
Microsoft Research продолжая исследования в области эффективного обучения и инференса языковых моделей (летом они выпускали статью про новый тип архитектур для замен трансформеров - Retentive Networks) выкатили однобитную трансформерную архитектуру BitNet (веса принимают значения только -1 и +1). На ряде задач BitNet умудряется выдавать качество сопоставимое с моделями в FP16. Авторы предлагают замену слоя nn.Linear на BitLinear для обучения бинарных весов. Сами же активации входных тензоров квантуются до 8-битных значений в ходе обучения. На этапе деквантизации в слое BitLinear точность активаций восстанавливается.
Что получаем в сухом остатке:
1) квантованные веса и активации снижают вычислительные затраты на обучение
2) градиенты и состояния оптимизатора сохраняют высокую точность, чтобы обеспечить стабильность обучения
3) для ускорения сходимости в начале обучения модели с бинарными весами применяют большие значения LR (маленькие изменения не приведут к обновлению бинарных весов)
4) scaling laws работают так же как и для fp16 трансформеров!
5) идеологически этот подход можно применять и для других типов архитектур (сами авторы планируют применить его в RetNet’ах)
Статья
@complete_ai
BitNet: Scaling 1-bit Transformers for Large Language Models
Microsoft Research продолжая исследования в области эффективного обучения и инференса языковых моделей (летом они выпускали статью про новый тип архитектур для замен трансформеров - Retentive Networks) выкатили однобитную трансформерную архитектуру BitNet (веса принимают значения только -1 и +1). На ряде задач BitNet умудряется выдавать качество сопоставимое с моделями в FP16. Авторы предлагают замену слоя nn.Linear на BitLinear для обучения бинарных весов. Сами же активации входных тензоров квантуются до 8-битных значений в ходе обучения. На этапе деквантизации в слое BitLinear точность активаций восстанавливается.
Что получаем в сухом остатке:
1) квантованные веса и активации снижают вычислительные затраты на обучение
2) градиенты и состояния оптимизатора сохраняют высокую точность, чтобы обеспечить стабильность обучения
3) для ускорения сходимости в начале обучения модели с бинарными весами применяют большие значения LR (маленькие изменения не приведут к обновлению бинарных весов)
4) scaling laws работают так же как и для fp16 трансформеров!
5) идеологически этот подход можно применять и для других типов архитектур (сами авторы планируют применить его в RetNet’ах)
Статья
@complete_ai