⭐️ Обучение модели W2NER для поиска именованных сущностей в текстах на русском языке
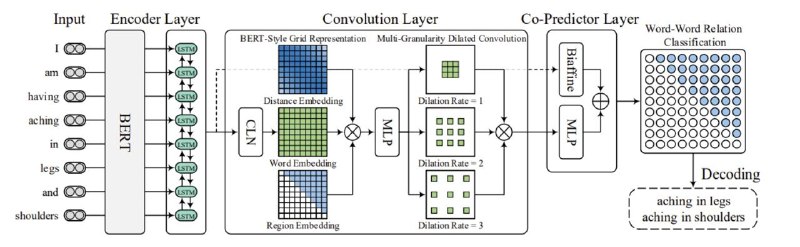
Задача распознавания сущностей (NER) постоянно возникает при машинной обработке документов, продолжается улучшение показателей качества и скорости работы алгоритмов для решения данной задачи. Предлагаю рассмотреть модель W2NER – классификатор попарных отношений слов в предложении. Далее я обучу модель на русскоязычном датасете и оценю качество её работы. Данные взяты из научной публикации: Unified Named Entity Recognition as Word-Word Relation Classification авторов Jingye Li и др.
➡️ Читать дальше
↪️ Github
@data_analysis_ml
Задача распознавания сущностей (NER) постоянно возникает при машинной обработке документов, продолжается улучшение показателей качества и скорости работы алгоритмов для решения данной задачи. Предлагаю рассмотреть модель W2NER – классификатор попарных отношений слов в предложении. Далее я обучу модель на русскоязычном датасете и оценю качество её работы. Данные взяты из научной публикации: Unified Named Entity Recognition as Word-Word Relation Classification авторов Jingye Li и др.
➡️ Читать дальше
↪️ Github
@data_analysis_ml