📕 Начал писать инструкцию, как прогать парсеры, чтобы все были довольны. Понял, что сначала нужно рассказать, что я понимаю под "парсером".
Для меня это программа, которая структурирует данные. Работать с табличками - удобно и понятно, а с картинками, большими текстами, html страницами, аудио/видео - не очень.
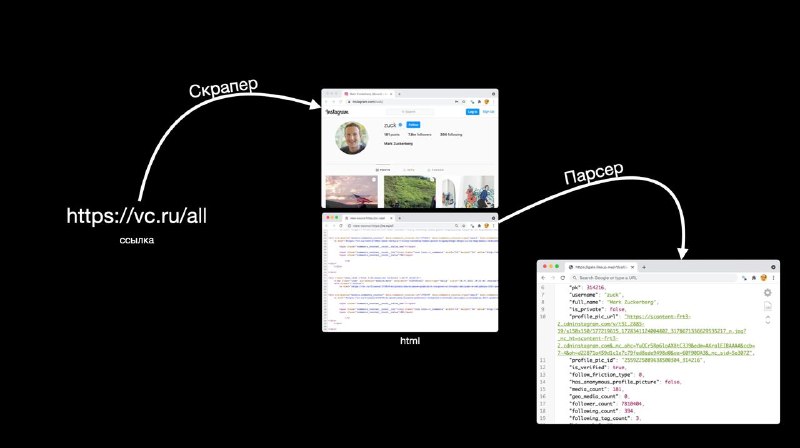
Если говорить про сбор данных с вебсайтов, то весь пайплайн можно разделить на три этапа:
1️⃣ по ссылке получить html страницу с данными (скрапинг)
2️⃣ извлечь оттуда все данные в удобном и правильном виде (парсинг)
3️⃣ положить все в базу данных (сейвинг??)
Зачастую с 1 и 3 пунктами все понятно, а вот 2 все делают как попало, из-за чего работать с результатами становится неудобно, хранить неэффективно, масштабируемость низкая. Именно про Best Practices парсинга я и расскажу скоро. Это будет не набор лайфхаков, как обходить защиты, а скорее "как оформить результаты так, чтобы все кайфанули".
Для меня это программа, которая структурирует данные. Работать с табличками - удобно и понятно, а с картинками, большими текстами, html страницами, аудио/видео - не очень.
Если говорить про сбор данных с вебсайтов, то весь пайплайн можно разделить на три этапа:
1️⃣ по ссылке получить html страницу с данными (скрапинг)
2️⃣ извлечь оттуда все данные в удобном и правильном виде (парсинг)
3️⃣ положить все в базу данных (сейвинг??)
Зачастую с 1 и 3 пунктами все понятно, а вот 2 все делают как попало, из-за чего работать с результатами становится неудобно, хранить неэффективно, масштабируемость низкая. Именно про Best Practices парсинга я и расскажу скоро. Это будет не набор лайфхаков, как обходить защиты, а скорее "как оформить результаты так, чтобы все кайфанули".