Написал статью про семантический поиск с помощью посгреса и OpenAI API.
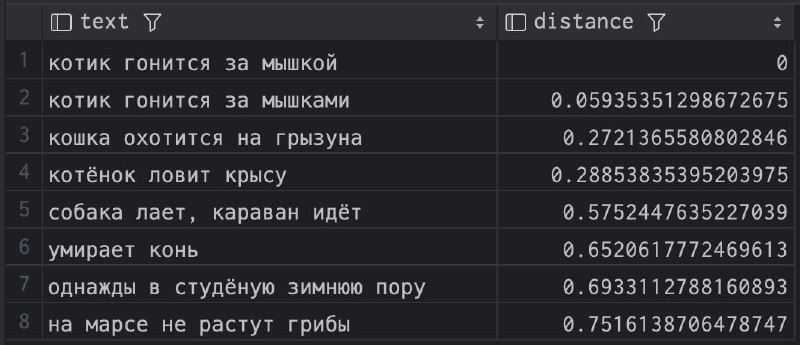
Казалось бы, в посгресе и так есть неплохой полнотекстовый поиск (tsvector/tsquery), и вы из коробки можете проиндексировать ваши тексты, а потом поискать по ним. Но на самом деле это не совсем то, что нужно — такой поиск работает лишь по чётким совпадениям слов. Т.е. postgres не догадается, что "кошка гонится за мышью" — это довольно близко к "котёнок охотится на грызуна". Как же победить такую проблему?
TLDR:
1. Преобразовываем наши тексты в наборы чисел (векторы) при помощи API openAI.
2. Сохраняем векторы в базе с помощью pgvector.
3. Легко ищем близкие друг к другу векторы или ищем их по вектору-запросу.
4. Ускоряем индексами.
Как всегда, буду рад плюсикам на Хабре:
https://habr.com/ru/companies/karuna/articles/809305/
Канал Cross Join. Подпишись
Казалось бы, в посгресе и так есть неплохой полнотекстовый поиск (tsvector/tsquery), и вы из коробки можете проиндексировать ваши тексты, а потом поискать по ним. Но на самом деле это не совсем то, что нужно — такой поиск работает лишь по чётким совпадениям слов. Т.е. postgres не догадается, что "кошка гонится за мышью" — это довольно близко к "котёнок охотится на грызуна". Как же победить такую проблему?
TLDR:
1. Преобразовываем наши тексты в наборы чисел (векторы) при помощи API openAI.
2. Сохраняем векторы в базе с помощью pgvector.
3. Легко ищем близкие друг к другу векторы или ищем их по вектору-запросу.
4. Ускоряем индексами.
Как всегда, буду рад плюсикам на Хабре:
https://habr.com/ru/companies/karuna/articles/809305/
Канал Cross Join. Подпишись