MEDPROMPT
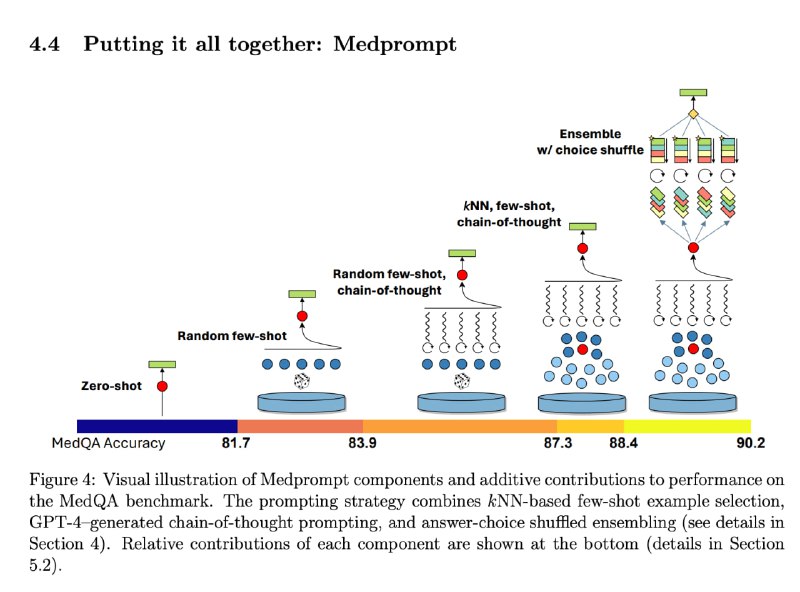
Как выжать максимум из LLM до того как заводить fine-tuning (который дорогой, долгий и сложный)? Ответ: продвинутый prompt engineering. Есть, значит, такой Medprompt, который со страшной силой бьёт бенчмарки на каких-либо узких доменах за счёт довольно простых приёмов.
Нам понадобятся 3 ингредиента:
1. kNN few-shot
2. Chain-of-Thought (CoT)
3. Ensemble choice shuffle
1. kNN few-shot: LLM сильно лучше понимают, что от них хотят, когда даёшь пару примеров (прямо как и люди). kNN few-shot практически тоже самое, что RAG (Retrieval Augmented Generation), с той лишь разницей, что если в RAG мы векторизуем сырую базу знаний (набор документов, разбитых на кусочки), то во few-shot kNN мы векторизуем запросы пар "запрос - ответ". Конкретно в Medprompt по запросу достаём "запрос - рассуждение (CoT) - ответ" (рассуждение и ответ могут быть как прописаны экспертом, так и сгенерированы LLM, а затем провалидированные экспертом).
Вы можете использовать в любом своём приложении few-shot как статичный (руками прописанный в промте), так и динамический (в kNN режиме, когда по запросу пользователя из векторной базы данных достаются похожие примеры запросов с их правильными ответами) – и это гарантированно повысит качество.
2. Chain-of-thought (CoT): цепочка рассуждений – по-простому, мы просто говорим модели подумать перед выбором финального ответа. Например,
CoT также значимо бустит качество генерации практически в любом приложении, переводя модель из режима "ответа сходу" на "обдуманное решение. Ведёт к дополнительным костам и секундам на "токены рассуждения", которые вы вероятно не будете показывать пользователю, но с GPT-4-Turbo цена и время стали приятнее.
#LLMOps
Как выжать максимум из LLM до того как заводить fine-tuning (который дорогой, долгий и сложный)? Ответ: продвинутый prompt engineering. Есть, значит, такой Medprompt, который со страшной силой бьёт бенчмарки на каких-либо узких доменах за счёт довольно простых приёмов.
Нам понадобятся 3 ингредиента:
1. kNN few-shot
2. Chain-of-Thought (CoT)
3. Ensemble choice shuffle
1. kNN few-shot: LLM сильно лучше понимают, что от них хотят, когда даёшь пару примеров (прямо как и люди). kNN few-shot практически тоже самое, что RAG (Retrieval Augmented Generation), с той лишь разницей, что если в RAG мы векторизуем сырую базу знаний (набор документов, разбитых на кусочки), то во few-shot kNN мы векторизуем запросы пар "запрос - ответ". Конкретно в Medprompt по запросу достаём "запрос - рассуждение (CoT) - ответ" (рассуждение и ответ могут быть как прописаны экспертом, так и сгенерированы LLM, а затем провалидированные экспертом).
Вы можете использовать в любом своём приложении few-shot как статичный (руками прописанный в промте), так и динамический (в kNN режиме, когда по запросу пользователя из векторной базы данных достаются похожие примеры запросов с их правильными ответами) – и это гарантированно повысит качество.
2. Chain-of-thought (CoT): цепочка рассуждений – по-простому, мы просто говорим модели подумать перед выбором финального ответа. Например,
Before crafting a reply, describe your observations in 3 sentences with clarifying strategy we should choose in <draft></draft> tags. Вариаций как организовать CoT масса. Главное, что это позволяет модели порефлексировать, набросать черновые варианты или выделить, на что обратить внимание, – до того как давать ответ. CoT также значимо бустит качество генерации практически в любом приложении, переводя модель из режима "ответа сходу" на "обдуманное решение. Ведёт к дополнительным костам и секундам на "токены рассуждения", которые вы вероятно не будете показывать пользователю, но с GPT-4-Turbo цена и время стали приятнее.
#LLMOps