RASMUSSEN SYSTEM MODEL
Например, в одном месте Грег делится ссылочкой на лекцию о том, как он мыслит о сложных системах со словами "I think this is the best (and only, really) framework I've seen on how to think about running a complex system". Лекция короткая, на 19 минут, и будет полезна любому инженеру и техническому менеджеру.
Идеи из лекции:
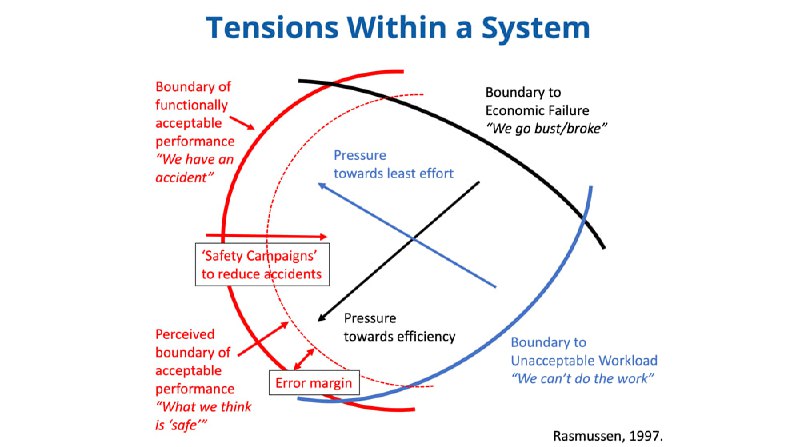
Сложная система адаптивна: её состояние в каждый момент времени "танцует" между тремя границами:
1. окупаемость (хватает ли нам денег её поддерживать?),
2. поддерживаемость (хватает ли нам рук её поддерживать?)
3. работоспособность (выдерживает ли нагрузку? учащаются ли ошибки, поломки, проблемы?)
Мы стремимся сделать систему дешевле (экономически эффективнее), отодвигая от границы окупаемости – и "автономнее", чтобы починка багов не отвлекала от добавления нового функционала. Обе эти оптимизации не даются бесплатно и ведут состояние системы – ближе к границе работоспособности (соответственно, система работает "на пике", значит, выше риск проблем).
Что же делать? Очерчивать пунктиром красные линии для допускаемой работоспособности? Вводить новые регламенты и субъективные ограничения перед физическими ограничениями?
Нет. Как сказано в начале, мы строим адаптивные системы, которые несмотря на желание сократить косты у менеджеров и на лень инженеров – на удивление работают и даже... относительно редко падают. Что обеспечивает эту адаптивность? – Люди.
Здесь мы приходим к важности мониторингов, алертов, опережающего реагирования, наконец, нашего собственного обучения по мере работы с системой. Это контрастирует с идеей, что достаточно наперёд просчитать на салфетке все нефункциональные требования, собрать систему по лекалу и закрыть сервера в бункере, чтоб никто не трогал.
https://www.youtube.com/watch?v=PGLYEDpNu60
P.S. Впрочем, не исключено, что через пару лет мы придём к практике навешивать пару-тройку LLM-агентов, завязанных на мониторинги и алерты, для оперативных починок и корректив наших систем, и тогда точно можно закрывать в бункерах!
Highly recommended.
Например, в одном месте Грег делится ссылочкой на лекцию о том, как он мыслит о сложных системах со словами "I think this is the best (and only, really) framework I've seen on how to think about running a complex system". Лекция короткая, на 19 минут, и будет полезна любому инженеру и техническому менеджеру.
Идеи из лекции:
Сложная система адаптивна: её состояние в каждый момент времени "танцует" между тремя границами:
1. окупаемость (хватает ли нам денег её поддерживать?),
2. поддерживаемость (хватает ли нам рук её поддерживать?)
3. работоспособность (выдерживает ли нагрузку? учащаются ли ошибки, поломки, проблемы?)
Мы стремимся сделать систему дешевле (экономически эффективнее), отодвигая от границы окупаемости – и "автономнее", чтобы починка багов не отвлекала от добавления нового функционала. Обе эти оптимизации не даются бесплатно и ведут состояние системы – ближе к границе работоспособности (соответственно, система работает "на пике", значит, выше риск проблем).
Что же делать? Очерчивать пунктиром красные линии для допускаемой работоспособности? Вводить новые регламенты и субъективные ограничения перед физическими ограничениями?
Нет. Как сказано в начале, мы строим адаптивные системы, которые несмотря на желание сократить косты у менеджеров и на лень инженеров – на удивление работают и даже... относительно редко падают. Что обеспечивает эту адаптивность? – Люди.
Здесь мы приходим к важности мониторингов, алертов, опережающего реагирования, наконец, нашего собственного обучения по мере работы с системой. Это контрастирует с идеей, что достаточно наперёд просчитать на салфетке все нефункциональные требования, собрать систему по лекалу и закрыть сервера в бункере, чтоб никто не трогал.
https://www.youtube.com/watch?v=PGLYEDpNu60
P.S. Впрочем, не исключено, что через пару лет мы придём к практике навешивать пару-тройку LLM-агентов, завязанных на мониторинги и алерты, для оперативных починок и корректив наших систем, и тогда точно можно закрывать в бункерах!
Highly recommended.