RAG: Retrieval Augmented Generation
Значит, дошли у Богдана руки наконец сделать один проектик с чат-ботом поверх базы знаний. Кто уже работал с knowledge-augmented chatbots – приглашаю в комментарии похвастаться, какой самый крутой конструктор лего собирали. Кто не работал – рассказываю как это заводить.
Проблема следующая: у ChatGPT, как и у других больших языковых моделей, контекст ограничен. Например, у GPT-3.5 он 4K токенов, у GPT-4 он 8К токенов (кто не знает, токен – это символ, слово или часть слова; например, посмотреть, на какие запчасти ChatGPT разбирает ваш промпт перед ответом, можно здесь; в английском 1000 токенов ≈ 750 слов). Размер контекста – это сколько текста может переварить модель перед ответом. Ясно, что в такое малое число токенов не запихать какую-то большую, длинную и специализированную базу знаний, с оглядкой на которую мы хотим чтобы модель отвечала.
Какие варианты решения проблемы?
Вариант №1 (долго-дорого-сложно): дообучить модель на свои данные
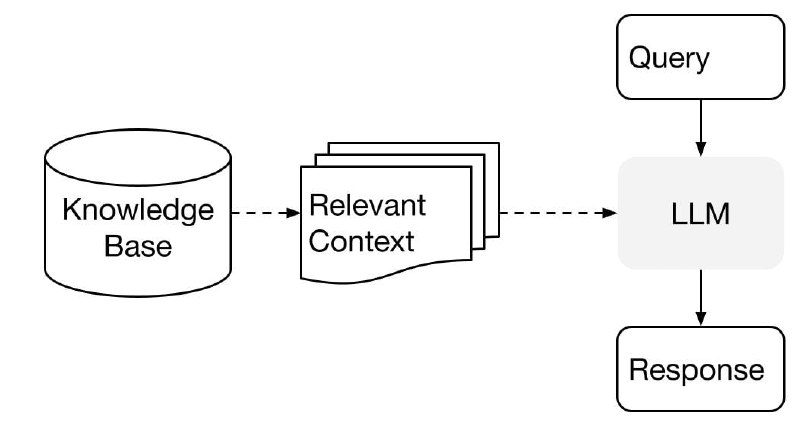
Вариант №2 (быстро-дёшево-легко): подтягивать релевантные контексты по запросу
Естественно, нас интересует второй вариант. Как он работает?
#LLMOps
Значит, дошли у Богдана руки наконец сделать один проектик с чат-ботом поверх базы знаний. Кто уже работал с knowledge-augmented chatbots – приглашаю в комментарии похвастаться, какой самый крутой конструктор лего собирали. Кто не работал – рассказываю как это заводить.
Проблема следующая: у ChatGPT, как и у других больших языковых моделей, контекст ограничен. Например, у GPT-3.5 он 4K токенов, у GPT-4 он 8К токенов (кто не знает, токен – это символ, слово или часть слова; например, посмотреть, на какие запчасти ChatGPT разбирает ваш промпт перед ответом, можно здесь; в английском 1000 токенов ≈ 750 слов). Размер контекста – это сколько текста может переварить модель перед ответом. Ясно, что в такое малое число токенов не запихать какую-то большую, длинную и специализированную базу знаний, с оглядкой на которую мы хотим чтобы модель отвечала.
Какие варианты решения проблемы?
Вариант №1 (долго-дорого-сложно): дообучить модель на свои данные
Вариант №2 (быстро-дёшево-легко): подтягивать релевантные контексты по запросу
Естественно, нас интересует второй вариант. Как он работает?
#LLMOps