🦙 LONGLLaMA: языковая модель, для обработки длинных контекстов из 256 000 токенов
Новый метод Focused Transformer (FOT) позволяет дообучать большие языковые модели для расширения эффективного понимания контекста.
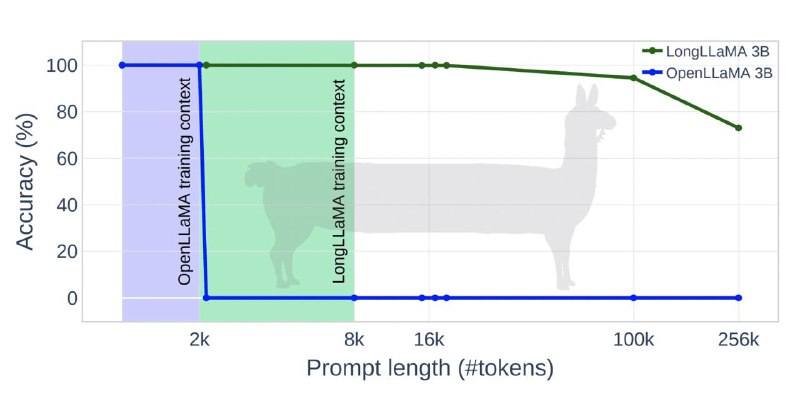
Для демонстрации метода исследователи дообучиили open source модели OpenLLaMA 3B и 7B, результирующая модель LONGLLAMA показала прогресс в точности в задачах, требующих понимания длинного контекста. Модель LONGLLAMA-3B достигла точности 94,5% при 100 тысячах токенов и 73% при 256 тысячах токенов, в то время как базовая модель OpenLLAMA не способна обрабатывать контексты, превышающие ее длину обучения в 2 тысячи токенов.
•Код
•Colab
bigdatai
Новый метод Focused Transformer (FOT) позволяет дообучать большие языковые модели для расширения эффективного понимания контекста.
Для демонстрации метода исследователи дообучиили open source модели OpenLLaMA 3B и 7B, результирующая модель LONGLLAMA показала прогресс в точности в задачах, требующих понимания длинного контекста. Модель LONGLLAMA-3B достигла точности 94,5% при 100 тысячах токенов и 73% при 256 тысячах токенов, в то время как базовая модель OpenLLAMA не способна обрабатывать контексты, превышающие ее длину обучения в 2 тысячи токенов.
•Код
•Colab
bigdatai