Недообученные нейросети — лучшие feature экстракторы
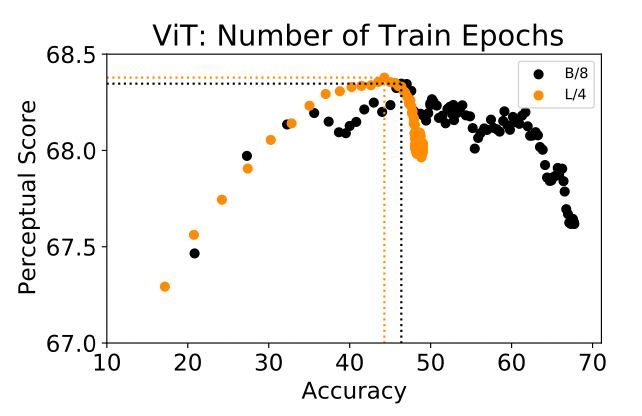
К удивительному выводу пришли две независимые группы исследователей из Google и Baidu — чем дольше учить нейронную сеть, тем хуже выразительная способность её фичей. То есть, не смотря на рост top-1 accuracy по мере обучения, качество её репрезентаций в какой-то момент начинает падать!
VGG и AlexNet давно известны тем, что их фичи отлично подходят для оценки perceptual similarity, но оказалось, что и все современные SOTA модели тоже подходят — просто надо брать не самый последний чекпоинт.
Более того, похоже, что для down-stream задач тоже лучше использовать эмбеддинги от недообученных моделей.
P.S. Проблема в том, что в какой-то момент модель становится настолько умной, что её фичи только она сама и понимает 🤷♂️
статья1, статья2
К удивительному выводу пришли две независимые группы исследователей из Google и Baidu — чем дольше учить нейронную сеть, тем хуже выразительная способность её фичей. То есть, не смотря на рост top-1 accuracy по мере обучения, качество её репрезентаций в какой-то момент начинает падать!
VGG и AlexNet давно известны тем, что их фичи отлично подходят для оценки perceptual similarity, но оказалось, что и все современные SOTA модели тоже подходят — просто надо брать не самый последний чекпоинт.
Более того, похоже, что для down-stream задач тоже лучше использовать эмбеддинги от недообученных моделей.
P.S. Проблема в том, что в какой-то момент модель становится настолько умной, что её фичи только она сама и понимает 🤷♂️
статья1, статья2