Заглянул на арену GPT. Если вы там не бываете, но интересуетесь борьбой GPTs - рекомендую заглядывать: [https://chat.lmsys.org/?leaderboard]
Интересные новости:
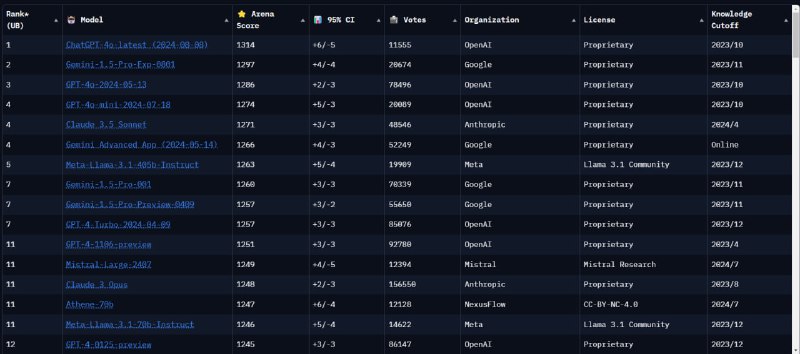
1. OpenAI все еще (или снова) лидирует, оставаясь единственной с ELO оценкой 1300+. Вообще каждый раз ощущение, что у них есть модель на порядок умнее, но релизить они ее будут только, когда другие покажут что-то достойное против текущей модели.
2. Впервые зашел в раздел тестов на русском языке – здесь Google сопоставим с OpenAI. Кто-нибудь знает, как было раньше?
3. Опенсорсные модели от Meta и Mistral близки к "прошлому" поколению моделей, которым 3-5 месяцев.
Про опенс сорс прикольно — эти модели требуют много вычислительных ресурсов, но и возможностей у них достаточно.
Также ждем полноценного релиза Grok 2 от Маска (последний раз оценка была 1281).
Вообще фан иногда "поиграть" в арену. Можно тут:
https://chat.lmsys.org/
И если вы не знаете как работает ELO score, короткое объяснение:
ELO рейтинг в LMSYS Chatbot Arena рассчитывается на основе парных баталий между моделями, где пользователи голосуют за лучшую, по их мнению, модель. После каждой баталии рейтинг моделей обновляется. Если модель с более высоким рейтингом проигрывает, она теряет больше очков, чем если бы выиграла.
@aihappens
Интересные новости:
1. OpenAI все еще (или снова) лидирует, оставаясь единственной с ELO оценкой 1300+. Вообще каждый раз ощущение, что у них есть модель на порядок умнее, но релизить они ее будут только, когда другие покажут что-то достойное против текущей модели.
2. Впервые зашел в раздел тестов на русском языке – здесь Google сопоставим с OpenAI. Кто-нибудь знает, как было раньше?
3. Опенсорсные модели от Meta и Mistral близки к "прошлому" поколению моделей, которым 3-5 месяцев.
Про опенс сорс прикольно — эти модели требуют много вычислительных ресурсов, но и возможностей у них достаточно.
Также ждем полноценного релиза Grok 2 от Маска (последний раз оценка была 1281).
Вообще фан иногда "поиграть" в арену. Можно тут:
https://chat.lmsys.org/
И если вы не знаете как работает ELO score, короткое объяснение:
ELO рейтинг в LMSYS Chatbot Arena рассчитывается на основе парных баталий между моделями, где пользователи голосуют за лучшую, по их мнению, модель. После каждой баталии рейтинг моделей обновляется. Если модель с более высоким рейтингом проигрывает, она теряет больше очков, чем если бы выиграла.
@aihappens