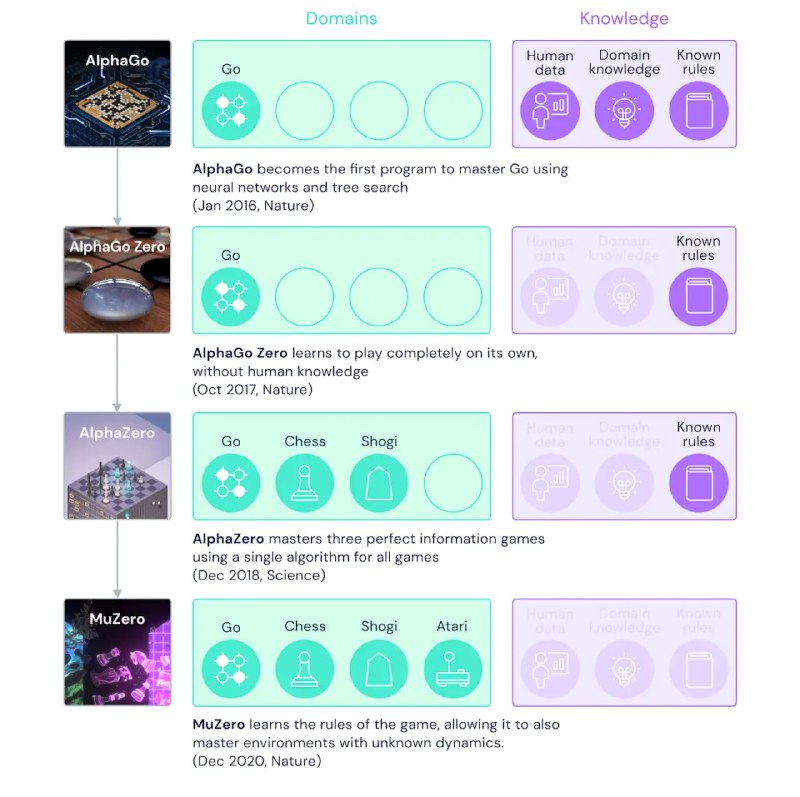
В 2016 DeepMind представил AlphaGo, которая наделала шума соревнуясь с людьми в го. Чуть позже за ней вышла AlphaZero, которая являлась более продвинутой версией и могла играть в разные игры включая шахматы и сёги (но при этом у них всех были прописаны правила игры).
А теперь, DeepMind публикует в Nature (😎) статью в которой описывается MuZero — еще более продвинутый алгоритм который может играть во все те же игры и даже игры на Атари без каких-либо вводных правил игры благодаря своему умению планировать стратегию в неизвестной среде. Главный нюанс тут в том, что это все одна сеть, которая может применятся к разным задачам, что является очень сложной задачей и важным шагом на пути к универсальным моделям.
Кажется мне, что если кто и приведет нас ксингулярности AGI, то это будет как раз эта разбалованная дочка Гугла.
А теперь, DeepMind публикует в Nature (😎) статью в которой описывается MuZero — еще более продвинутый алгоритм который может играть во все те же игры и даже игры на Атари без каких-либо вводных правил игры благодаря своему умению планировать стратегию в неизвестной среде. Главный нюанс тут в том, что это все одна сеть, которая может применятся к разным задачам, что является очень сложной задачей и важным шагом на пути к универсальным моделям.
Кажется мне, что если кто и приведет нас к