Dependency Inversion Principle
Принцип инверсии зависимостей (DIP) часто путают с техникой внедрения зависимостей (DI), но это разные вещи, служащие разным целям. Начнем с самой инверсии.
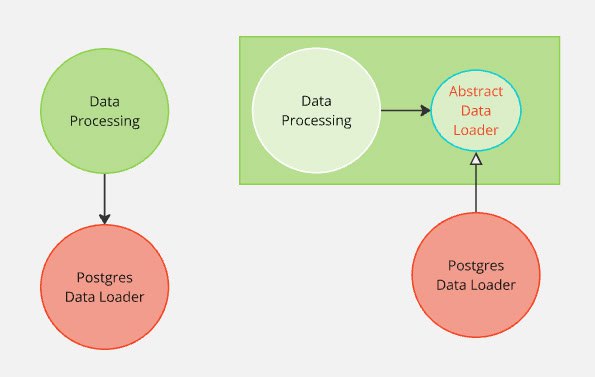
Представим ситуацию: у нас есть компонент
Инверсия этой зависимости получится когда компонент
Чтобы добиться такой инверсии, мы выделяем требования компонента
• Было:
• Стало:
Обратите внимание, что я говорю о компонентах - это могут быть модули, группы классов или даже функции. Так же нигде не было речи о том, как D будет подставлен вместо B, мы можем использовать любые подходы для организации этого, но конечно же DI зачастую удобнее.
Непосредственно сам принцип инверсии зависимостей говорит, что более абстрактные части код не должны знать о более конкретных, более универсальные о частных, более высокоуровневые о низкоуровневых. Иногда это выполняется само по себе, но иногда мы для этого специально инвертируем зависимости.
Например, коду расчета заработной платы может понадобиться выводить результат на экран. И, скорее всего, коду расчета совершенно не важно, какое у экрана разрешение и вообще, действительно ли это настоящий экран. На лицо зависимость, которую мы можем инвертировать. При этом, у нас есть код, который непосредственно занимается выводом на экран, у него есть зависимость от самого экрана, однако они на одном уровне и инверсия не требуется.
Цели этого - борьба со сложностью программы, облегчение тестирования, увеличение гибкости системы, изоляция будущих изменений, упрощение переиспользования кода. Имея понятные абстракции, мы можем быстрее понять, что делает код, не вдаваясь в детали реализации зависимостй. Мы можем подменять реализации зависимостей, если нам это понадобится, мы с большей вероятностью не сломаем другой код, если не нарушаем контракт, в отличие от ситуации, когда контракта нет.
У DIP есть цена. Если без его использования мы могли сразу перейти к реализации и увидеть, как всё устроено, с DIP эту реализацию ещё надо поискать. Если абстракция выделена плохо, недостаточно полно описывает требования или наоборот загрязнена ненужными деталями, мы платим цену DIP, но не получаем его преимуществ.
Дополнительные материалы:
• https://martinfowler.com/articles/dipInTheWild.html
• https://blog.cleancoder.com/uncle-bob/2016/01/04/ALittleArchitecture.html
• https://martinfowler.com/bliki/TestDouble.html
Принцип инверсии зависимостей (DIP) часто путают с техникой внедрения зависимостей (DI), но это разные вещи, служащие разным целям. Начнем с самой инверсии.
Представим ситуацию: у нас есть компонент
А и ему для работы нужен компонент D. Например, для обработки данных нам надо их загрузить из БД. Это прямая зависимость: компонент А знает о компоненте D, а компонент D не знает о компоненте А. Под знанием я имею в виду использование в коде типов, импортов, да и в целом проектирование одного куска кода исходя из того, как устроен второй.Инверсия этой зависимости получится когда компонент
А перестанет знать о компоненте D, а вместо этого компонент D станет знать о компоненте А. То есть обработка данных не знает о том, как они загружаются, но код загрузки данных может знать, что их будут обрабатывать. Держим в голове, что D все ещё должен использоваться внутри А - мы не меняем логику кода, мы только работаем с тем, как устроена зависимость.Чтобы добиться такой инверсии, мы выделяем требования компонента
А к зависимости. Это его часть. Они часто могут быть выражены в виде интерфейса или абстрактного класса (B). В свою очередь, компонент D будет реализовывать эти требования. После этих манипуляций мы получаем, что компонент А ничего не знает о настоящем D. В свою очередь, D начинает знать о требованиях А. В рамках примера мы получаем интерфейс "Загрузчик данных" и реализацию "ЗагрузчикДанныхSQL".• Было:
А -знает-> D. D не знает об А. А использует D.• Стало:
А не знает D. D -знает-> о требованиях А. А все ещё использует D, но думает только о B.Обратите внимание, что я говорю о компонентах - это могут быть модули, группы классов или даже функции. Так же нигде не было речи о том, как D будет подставлен вместо B, мы можем использовать любые подходы для организации этого, но конечно же DI зачастую удобнее.
Непосредственно сам принцип инверсии зависимостей говорит, что более абстрактные части код не должны знать о более конкретных, более универсальные о частных, более высокоуровневые о низкоуровневых. Иногда это выполняется само по себе, но иногда мы для этого специально инвертируем зависимости.
Например, коду расчета заработной платы может понадобиться выводить результат на экран. И, скорее всего, коду расчета совершенно не важно, какое у экрана разрешение и вообще, действительно ли это настоящий экран. На лицо зависимость, которую мы можем инвертировать. При этом, у нас есть код, который непосредственно занимается выводом на экран, у него есть зависимость от самого экрана, однако они на одном уровне и инверсия не требуется.
Цели этого - борьба со сложностью программы, облегчение тестирования, увеличение гибкости системы, изоляция будущих изменений, упрощение переиспользования кода. Имея понятные абстракции, мы можем быстрее понять, что делает код, не вдаваясь в детали реализации зависимостй. Мы можем подменять реализации зависимостей, если нам это понадобится, мы с большей вероятностью не сломаем другой код, если не нарушаем контракт, в отличие от ситуации, когда контракта нет.
У DIP есть цена. Если без его использования мы могли сразу перейти к реализации и увидеть, как всё устроено, с DIP эту реализацию ещё надо поискать. Если абстракция выделена плохо, недостаточно полно описывает требования или наоборот загрязнена ненужными деталями, мы платим цену DIP, но не получаем его преимуществ.
Дополнительные материалы:
• https://martinfowler.com/articles/dipInTheWild.html
• https://blog.cleancoder.com/uncle-bob/2016/01/04/ALittleArchitecture.html
• https://martinfowler.com/bliki/TestDouble.html