Masked Autoencoders Are Scalable Vision Learners
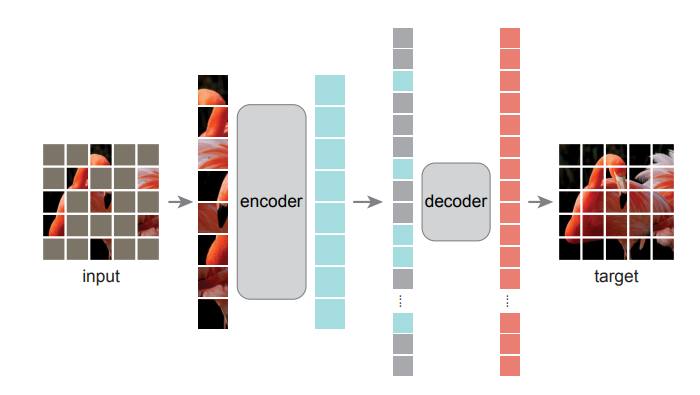
Ещё одна идея, которая казалось бы была на поверхности, and yet… Берём картиночный автоэнкодер, делим картинку на патчи, прячем их в случайном порядке, и просим декодер восстановить изображение (в режиме self-supervised).
Авторы (Facebook/Meta AI), обнаружили, что скрытие большой части входного изображения, например, 75%, дает нетривиальную и осмысленную задачу для self-supervised обучения. Оказалось, что в такой формулировке, автоэнкодер обучается в ~3 раза быстрее (чем если бы мы учили на изображениях без масок).
Более того, оказалось, что если к такому обученному автоэнкодеру прикрутить голову на классификацию (например), то она будет показывать SOTA результаты. Так же, авторы показывают, что при масштабировании датасета, результаты только улучшаются.
📎 Статья
#selfSupervised #autoencoders #images
Ещё одна идея, которая казалось бы была на поверхности, and yet… Берём картиночный автоэнкодер, делим картинку на патчи, прячем их в случайном порядке, и просим декодер восстановить изображение (в режиме self-supervised).
Авторы (Facebook/Meta AI), обнаружили, что скрытие большой части входного изображения, например, 75%, дает нетривиальную и осмысленную задачу для self-supervised обучения. Оказалось, что в такой формулировке, автоэнкодер обучается в ~3 раза быстрее (чем если бы мы учили на изображениях без масок).
Более того, оказалось, что если к такому обученному автоэнкодеру прикрутить голову на классификацию (например), то она будет показывать SOTA результаты. Так же, авторы показывают, что при масштабировании датасета, результаты только улучшаются.
📎 Статья
#selfSupervised #autoencoders #images