Zero-Shot NLP Task Generalization
Huggingface совместно с исследователями из 250(!) институтов представили модель T0, которая обходит GPT-3 и при этом в десятки раз компактнее.
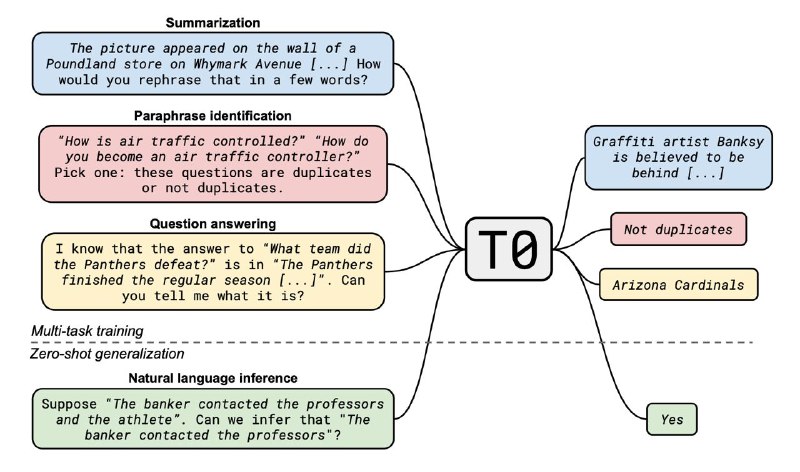
Ещё в статьях про GPT-2 и GPT-3 показали, что языковые модели умеют не только дописывать текст, но и кучу всего классного: QA, summarization, translation и тд. Главное, в правильном формате текст подавать — например, для summarization в конце нужно дописать «TL;DR:» и модель выдаст краткое содержание всего что выше. Это называется prompt engineering, и, по сути, это побочный эффект.
А что если во время обучения сфокусироваться на этом «побочном эффекте»? Авторы статьи создали prompted-task датасет: они взяли все главные NLP бэнчмарки и переписали их в prompted формате. Потом они взяли модель T5 и дообучили на всём этом.
В итоге они получили SOTA почти везде, даже на тех задачах, которые модель никогда не видела (они проверили). Это и есть zero-shot task generalization.
Статья, GitHub, Huggingface
Huggingface совместно с исследователями из 250(!) институтов представили модель T0, которая обходит GPT-3 и при этом в десятки раз компактнее.
Ещё в статьях про GPT-2 и GPT-3 показали, что языковые модели умеют не только дописывать текст, но и кучу всего классного: QA, summarization, translation и тд. Главное, в правильном формате текст подавать — например, для summarization в конце нужно дописать «TL;DR:» и модель выдаст краткое содержание всего что выше. Это называется prompt engineering, и, по сути, это побочный эффект.
А что если во время обучения сфокусироваться на этом «побочном эффекте»? Авторы статьи создали prompted-task датасет: они взяли все главные NLP бэнчмарки и переписали их в prompted формате. Потом они взяли модель T5 и дообучили на всём этом.
В итоге они получили SOTA почти везде, даже на тех задачах, которые модель никогда не видела (они проверили). Это и есть zero-shot task generalization.
Статья, GitHub, Huggingface