Fine-Tuned Transformers Show Clusters of Similar Representations Across Layers
Оказывается, после файн-тюнинга, некоторые слои в трансформерах начинают «игнорироваться». Видимо, модель считает, что проще их не учить, а просто выключить (перекинуть через skip-connection).
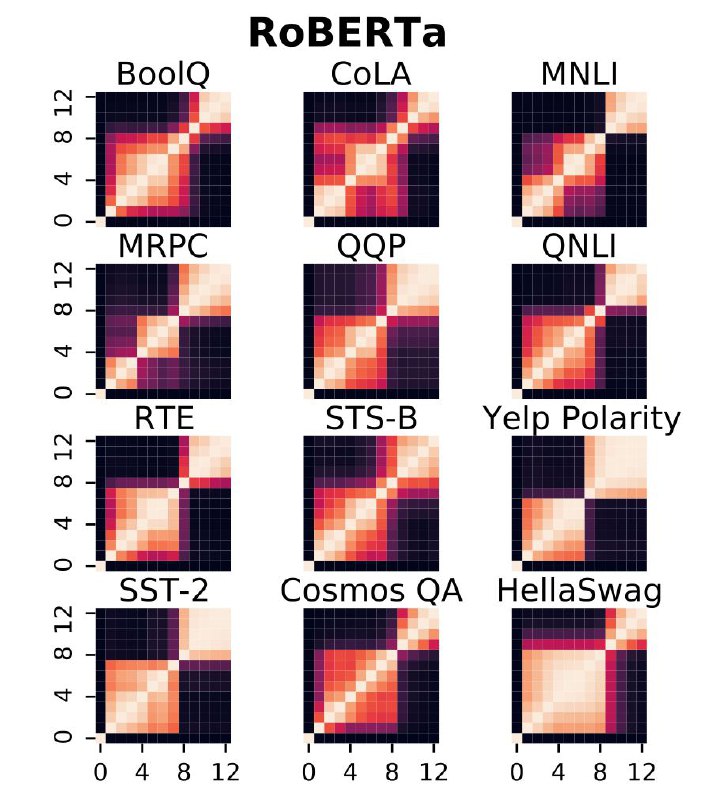
Это ещё одна работа, которая использует новомодный Centered Kernel Alignment для оценки похожести активаций на разных слоях. Тут зафайнтюнили RoBERTa и ALBERT на 12 NLU бэнчмарках, и, оказалось, что у них возникают кластеры слоёв с практически идентичными активациями, которых не было до дообучения.
Раз активации одинаковые на разных слоях, то, может быть, стоит выкинуть всё что между ними? Так авторы и сделали, и увидели, что перформанс моделей упал совсем чуть-чуть (~1%). Выходит, что CKA можно использовать для такого хитрого сжатия трансформеров.
P.S. Вот вам и доказательство того, что даже трансформеры бывают ленивыми 🦥
Статья
Оказывается, после файн-тюнинга, некоторые слои в трансформерах начинают «игнорироваться». Видимо, модель считает, что проще их не учить, а просто выключить (перекинуть через skip-connection).
Это ещё одна работа, которая использует новомодный Centered Kernel Alignment для оценки похожести активаций на разных слоях. Тут зафайнтюнили RoBERTa и ALBERT на 12 NLU бэнчмарках, и, оказалось, что у них возникают кластеры слоёв с практически идентичными активациями, которых не было до дообучения.
Раз активации одинаковые на разных слоях, то, может быть, стоит выкинуть всё что между ними? Так авторы и сделали, и увидели, что перформанс моделей упал совсем чуть-чуть (~1%). Выходит, что CKA можно использовать для такого хитрого сжатия трансформеров.
P.S. Вот вам и доказательство того, что даже трансформеры бывают ленивыми 🦥
Статья