Дропаут градиентов: как не испортить модель во время файн-тюнинга (Alibaba)
Во время файн-тюнинга очень глубокие модели (e.g. BERT, GPT) начинают тупеть, оверфитясь на новые данные. Ведь для огромной capacity таких моделей, информации во время дообучения просто недостаточно.
Частично эту проблему решала специальная регуляризация: MSE лосс между старыми весами и новыми (RecAdam). Но похоже, что в Alibaba придумали как полностью решить эту проблему — они предлагают дообучать не всю сеть сразу, а только случайно выбранные сабсеты параметров.
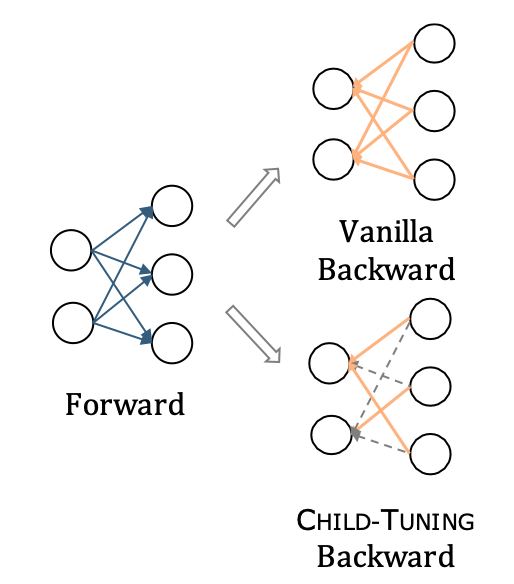
По сути они делают dropout градиентов. Во время инференса задействуются все параметры, а во время бэкварда часть градиентов зануляется. Это эффективно уменьшает capacity нейронки и спасат её от оверфита.
В итоге они получили лучшие результаты на NLI и NLU бэнчмарках для кучи трансформеров. Ещё они доказали пару теорем, показывающих, что такая регуляризация позволяет находить flat local minima, что классно для обобщающей способности (тык).
Статья, GitHub
Во время файн-тюнинга очень глубокие модели (e.g. BERT, GPT) начинают тупеть, оверфитясь на новые данные. Ведь для огромной capacity таких моделей, информации во время дообучения просто недостаточно.
Частично эту проблему решала специальная регуляризация: MSE лосс между старыми весами и новыми (RecAdam). Но похоже, что в Alibaba придумали как полностью решить эту проблему — они предлагают дообучать не всю сеть сразу, а только случайно выбранные сабсеты параметров.
По сути они делают dropout градиентов. Во время инференса задействуются все параметры, а во время бэкварда часть градиентов зануляется. Это эффективно уменьшает capacity нейронки и спасат её от оверфита.
В итоге они получили лучшие результаты на NLI и NLU бэнчмарках для кучи трансформеров. Ещё они доказали пару теорем, показывающих, что такая регуляризация позволяет находить flat local minima, что классно для обобщающей способности (тык).
Статья, GitHub