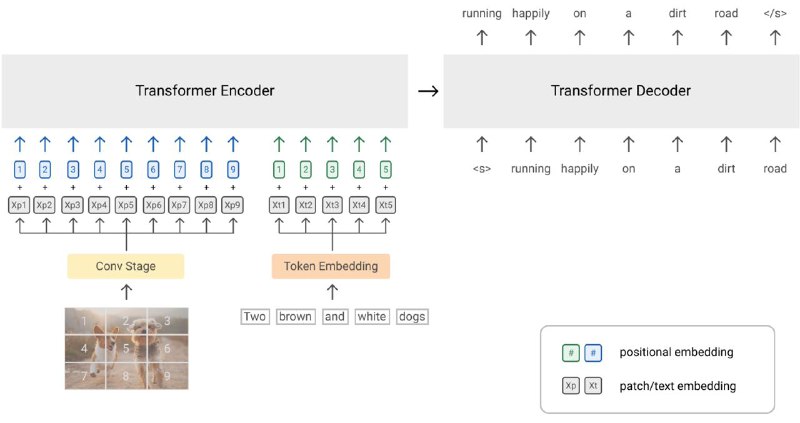
SimVLM step-by-step
1. Будем учить модель на парах картинка-описание (датасет).
2. Картинку разрезаем на прямоугольники — визуальные токены.
3. Каждый визуальный токен пропускаем сначала через Conv-часть резнета, а затем через ViT и получаем визуальные эмбеддинги.
4. Токенизируем текстовое описание картинки.
5. Делим список текстовых токенов на две части.
6. Левую часть эмбеддим линейным слоем и конкатенируем со списком визуальных эмбеддингов. Это будет инпут модели.
7. Аггрегируем этот список эмбеддингов с помощью bidirectional трансформера (наподобие BERT).
8. Декодим всё это с помощью авторегрессионного трансформера (наподобие GPT).
9. С помощью Cross-Entropy Loss учим модель генерировать именно правую часть описания картинки.
10. Тренируем модель ровно одну эпоху.
Готово!
1. Будем учить модель на парах картинка-описание (датасет).
2. Картинку разрезаем на прямоугольники — визуальные токены.
3. Каждый визуальный токен пропускаем сначала через Conv-часть резнета, а затем через ViT и получаем визуальные эмбеддинги.
4. Токенизируем текстовое описание картинки.
5. Делим список текстовых токенов на две части.
6. Левую часть эмбеддим линейным слоем и конкатенируем со списком визуальных эмбеддингов. Это будет инпут модели.
7. Аггрегируем этот список эмбеддингов с помощью bidirectional трансформера (наподобие BERT).
8. Декодим всё это с помощью авторегрессионного трансформера (наподобие GPT).
9. С помощью Cross-Entropy Loss учим модель генерировать именно правую часть описания картинки.
10. Тренируем модель ровно одну эпоху.
Готово!