Do Vision Transformers See Like Convolutional Neural Networks? (by Google)
В Google Brain попытались разобраться, чем отличается зрение трансформеров от CNN.
Они обучили оба типа моделей на одном и том же датасете, а затем статистически сравнивали активации с помощью Centered Kernel Alignment.
Выводы:
1. Трансформеры извлекают больше глобальной информации из картинки, чем CNN. Они «видят» картинку целиком.
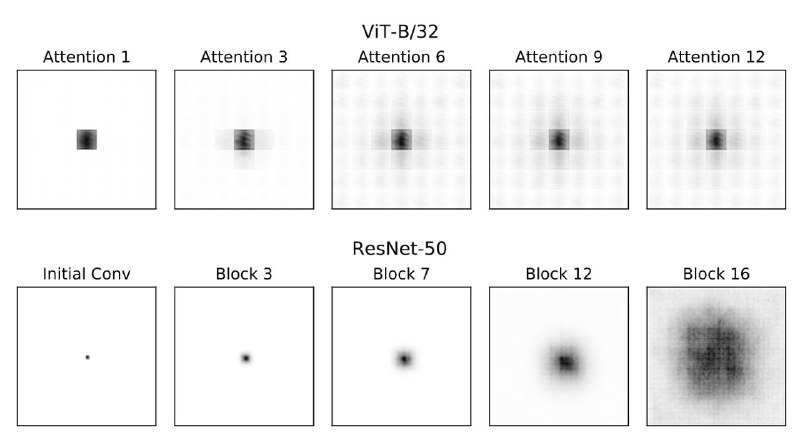
2. Они сначала учат глобальные фичи, и только потом локальные. Из-за этого receptive field растёт почти мгновенно в отличие от CNN (см. картинку).
3. Но для того чтобы выучить локальные фичи, трансформерам нужно очень много обучающих данных.
4. Skip-connections в трансформерах делают больше полезной работы, чем в резнетах.
5. Информация о позиции объекта в трансформерах сохраняется более точно.
6. MLP-Mixer ведёт себя скорее как ViT, чем ResNet.
P.S. Ещё одно подтверждение того, что сильный inductive bias (e.g., конволюции) только мешает нейронкам учиться 🤦♂️
Статья
В Google Brain попытались разобраться, чем отличается зрение трансформеров от CNN.
Они обучили оба типа моделей на одном и том же датасете, а затем статистически сравнивали активации с помощью Centered Kernel Alignment.
Выводы:
1. Трансформеры извлекают больше глобальной информации из картинки, чем CNN. Они «видят» картинку целиком.
2. Они сначала учат глобальные фичи, и только потом локальные. Из-за этого receptive field растёт почти мгновенно в отличие от CNN (см. картинку).
3. Но для того чтобы выучить локальные фичи, трансформерам нужно очень много обучающих данных.
4. Skip-connections в трансформерах делают больше полезной работы, чем в резнетах.
5. Информация о позиции объекта в трансформерах сохраняется более точно.
6. MLP-Mixer ведёт себя скорее как ViT, чем ResNet.
P.S. Ещё одно подтверждение того, что сильный inductive bias (e.g., конволюции) только мешает нейронкам учиться 🤦♂️
Статья