Что такое CLIP и как он работает?
Почти полгода прошло с тех пор, как OpenAI представила CLIP: Contrastive Language–Image Pre-training. Это было то, чего мы так долго ждали — универсальная модель, которая одинаково классно понимает и картинки и текст, открывая возможности для исследований на стыке CV и NLP.
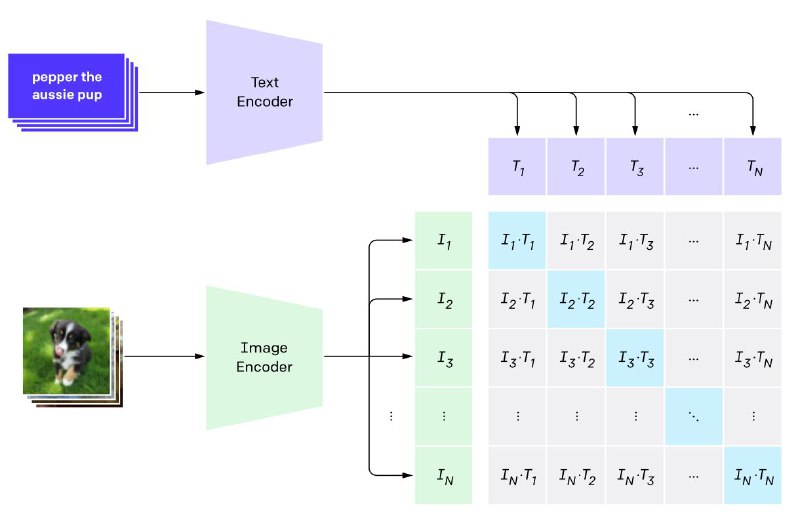
Если коротко, то эта штука энкодит картинки и их описания в близкие (в идеале — одинаковые) эмбеддинги. Но если копнуть глубже, то эта модель научилась выявлять «open-set visual concepts from natural language» и показывает удивительные способности к генерализации. Она понимает высокие уровни абстракции и неявные связи между ними.
CLIP состоит из двух моделей: image-encoder (ViT или resnet50) и text-encoder (transformer). Для обучения собрали огроменный датасет из 400M картинок с описаниями из интернета. Энкодеры одновременно учатся генерировать эмбеддинги для картинок и описаний, максимизируя косинус между правильными парами из батча и минимизирую между всеми остальными.
Статья, GitHub, блог
Почти полгода прошло с тех пор, как OpenAI представила CLIP: Contrastive Language–Image Pre-training. Это было то, чего мы так долго ждали — универсальная модель, которая одинаково классно понимает и картинки и текст, открывая возможности для исследований на стыке CV и NLP.
Если коротко, то эта штука энкодит картинки и их описания в близкие (в идеале — одинаковые) эмбеддинги. Но если копнуть глубже, то эта модель научилась выявлять «open-set visual concepts from natural language» и показывает удивительные способности к генерализации. Она понимает высокие уровни абстракции и неявные связи между ними.
CLIP состоит из двух моделей: image-encoder (ViT или resnet50) и text-encoder (transformer). Для обучения собрали огроменный датасет из 400M картинок с описаниями из интернета. Энкодеры одновременно учатся генерировать эмбеддинги для картинок и описаний, максимизируя косинус между правильными парами из батча и минимизирую между всеми остальными.
Статья, GitHub, блог